Related to: Project
GitHub - 404Vector/Competition.DACON.ArtWorksPainterClassification: Dacon 화가 이미지 분류
Dacon 예술 작품 화가 분류 AI 경진대회 model 폴더 .
https://github.com/404Vector/Competition.DACON.ArtWorksPainterClassification
요약
==My Contribute==
- ==팀 내 최대 Code Contributor==
- ==EDA==
- ==Data download & directory setting 자동화 Script 작성==
- ==WandB 연동==
- ==Train, Inferrence Script 작성==
- ==Efficientnet v2실험==
- ==ViT 모델 실험==
Task
- Classification Task, 예술 작품을 화가 별로 분류하는 AI 모델 개발
Score
- Macro F1 Score
Data
- Train Data
- 이미지, 화가, 화가별 장르 정보
- Test Data
- 이미지(원본을 랜덤으로 1/4 crop)
개요
월간 데이콘 예술 작품 화가 분류 AI 경진대회
화가 분류는 많은 연구가 이루어지고 있는 문제로, 주로 이미지 처리 및 기계 학습의 전통적인 접근 방식을 통해 꾸준하게 연구되어왔습니다. 더 나아가 현재에는 화가의 작품을 흉내내거나, 직접 예술 작품을 창조해내는 GAN을 활용한 생성 모델 연구까지 이루어지고 있습니다.
이번 월간 데이콘 26은 예술 작품을 화가 별로 분류하는 대회입니다.
더 나아가 예술 작품의 일부분만을 가지고도 올바르게 분류해낼 수 있어야합니다.예술 작품의 일부분만 주어지는 테스트 데이터셋에 대해 올바르게 화가를 분류해낼 수 있는 예술 작품의 전문가인 AI 모델을 만들어주세요.
본론
EDA
-
장르와 화가의 상관 관계 → 화가별로 하나의 장르만 있는 사람도 있으나, 여러 장르를 그리는 화가도 있음
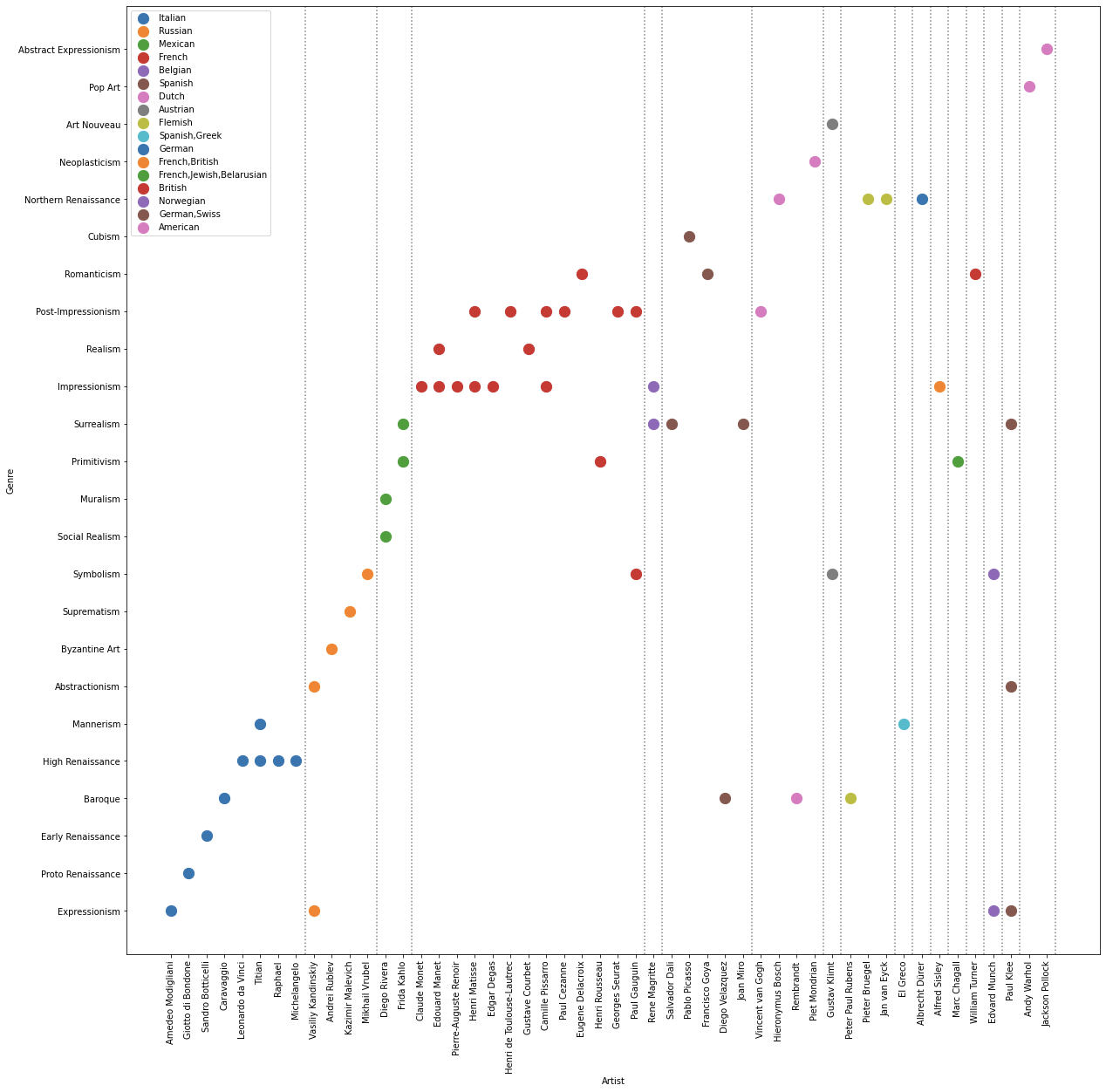
-
화가와 그림 크기의 상관 관계 → 화가별로 그리는 그림의 크기가 어느정도 유사함
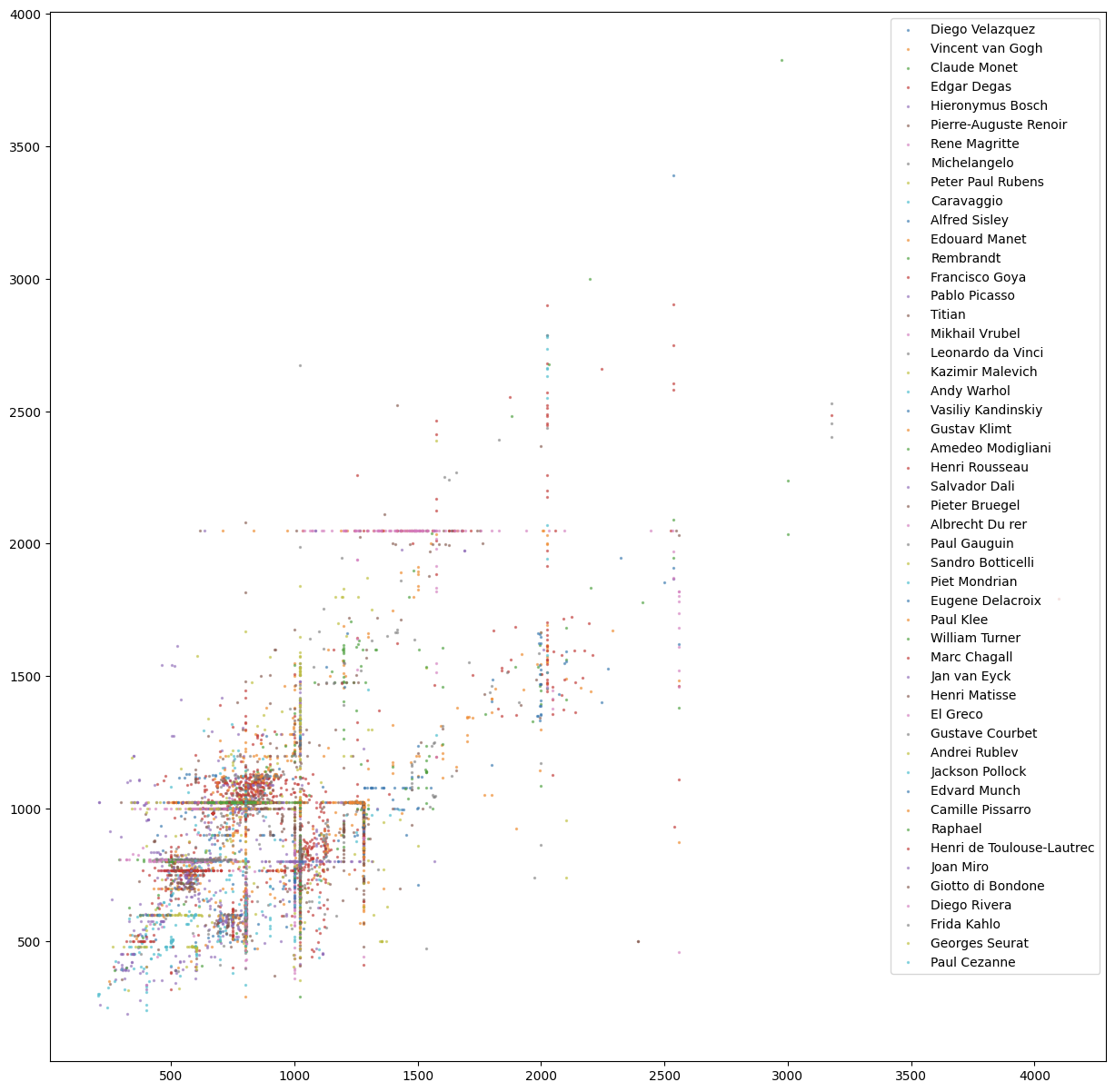
-
화가 별 그림 개수 → 화가 별로 데이터 개수가 다름(Class imbalance) 존재
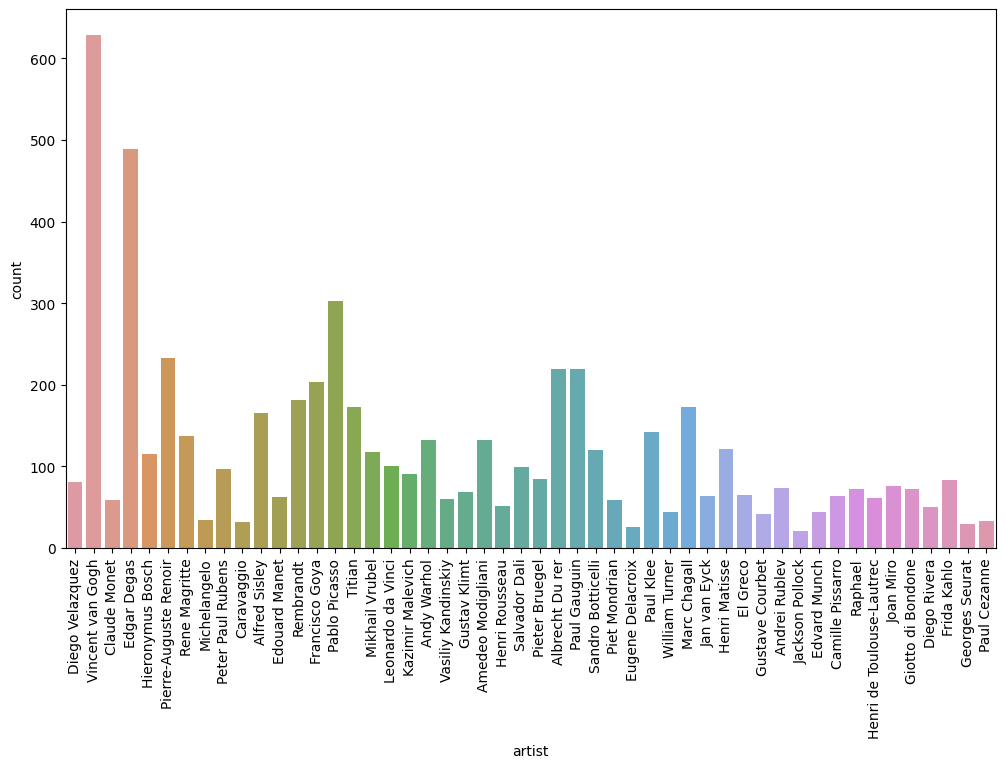
-
화가 별 그림의 RGB Mean & Std.(일부) → 화가별로 사용하는 색에 경향성을 보였음
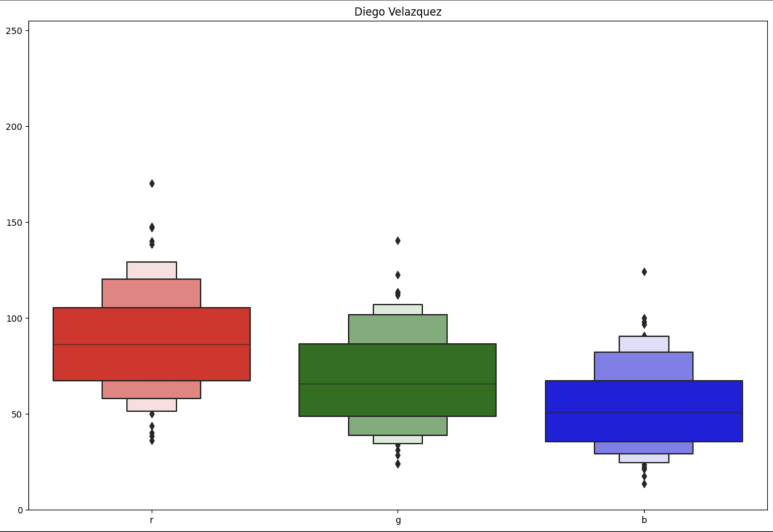
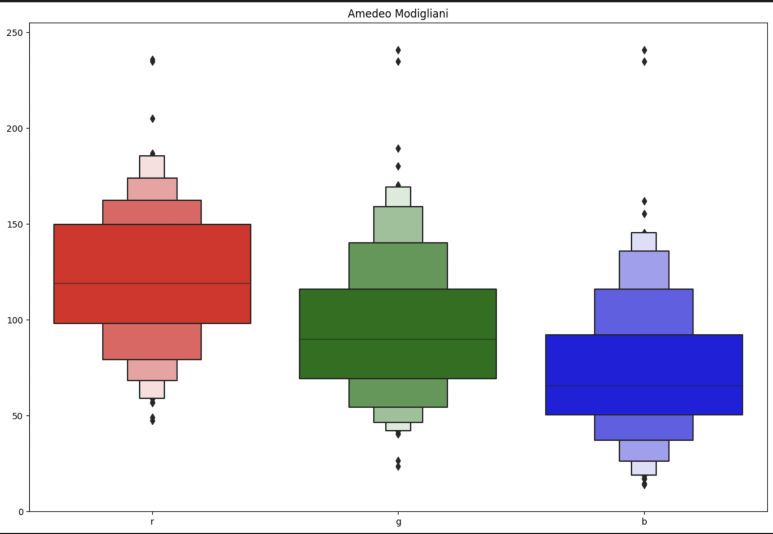
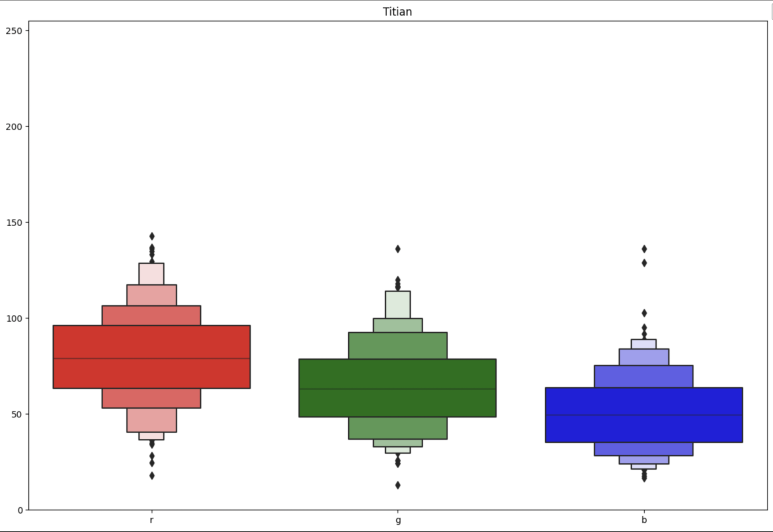
Data Sampling
-
Train / Valid Split
Stratified sampling으로 Train과 Valid Set을 나눔
-
Class Imbalance
Data Oversamplig을 사용해 부족한 화가 그림의 경우 더 많이 load되도록 설정
Augmentation
-
RandomCrop
-
Horizontal & Vertical Flip
-
Resize
-
Cutmix
색조나 채도를 바꾸거나 Geometric Augmentation을 할 경우 화풍이나 색감이 왜곡될 것이라고 판단
다른 기법은 사용하지 않음
Loss
-
Cross Entropy Loss
→ Oversampling을 사용했기 때문에 Focal loss 미사용
Optimizer
- Adam
Scheduler
- Step LR
Model
- ResNeXt
- Efficientnet b4
- Max ViT
- SwinT
- Regnet
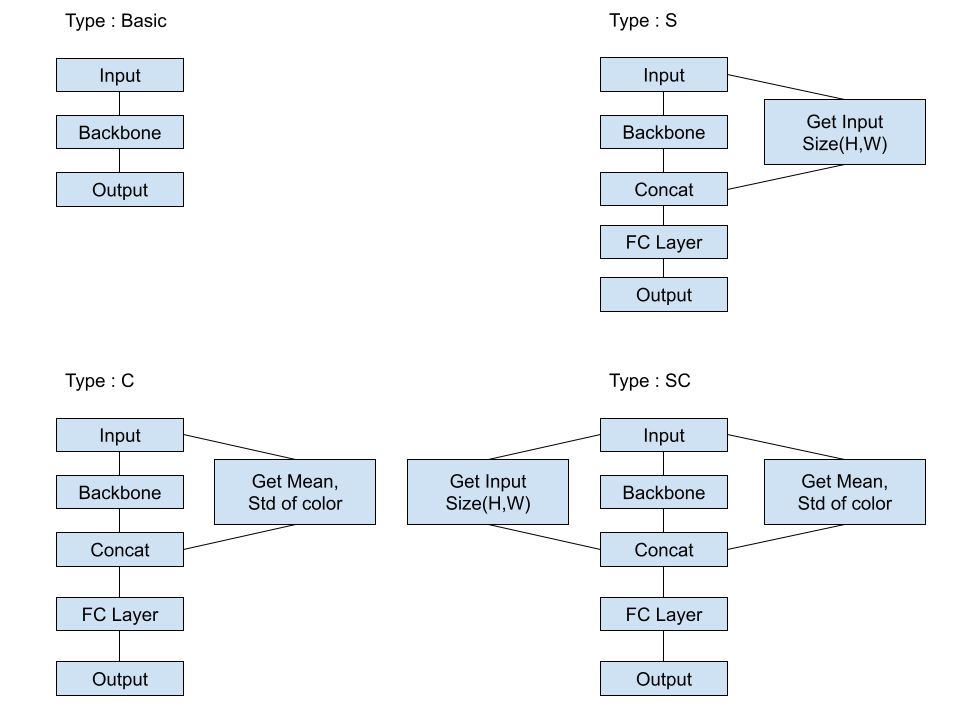
→ Model 별로 Size나 RGB 평균, 표준 편차 값을 추가로 embed, 결과 모두 embed 한 것이 가장 성능이 좋았음
단, ViT의 경우 사용하지 않은 것이 성능이 좋았음
Ensemble
-
CSV result hard voting
각 모델(ResNeXt, Efficientnet b4, Max ViT, SwinT, Regnet)의 Best Case를 ensemble
-
Result
Best Case(Efficientnet b4, 0.7967) → ==Ensemble 0.8534==
결론
-
Ranking

-
느낀점
-
EDA를 통해 얻은 인사이트(작가별 크기와 색에 따른 경향성)로 기존 Classification model에 정보를 추가로 concat하여 classification을 수행했을 때, 점수 상승이 있었고 EDA의 중요성을 느끼게 되었다.
-
EDA 과정에서 Raw Data(이미지)를 많이 보게 되었고, 이를 토대로 Augmentation 의사결정 과정에서 색이나 그림 자체를 왜곡하는 기법들을 실험하지 않고 제외할 수 있었다. Raw Data를 눈으로 보는 것이 매우 중요하다고 느껴졌다.
-
하나의 잘 된 모델보다 다양한 모델을 사용하는 것이 다양한 관점에서 볼 수 있다고 판단하여 다양한 모델을 훈련시켰다. 모델들의 결과는 0.7에서 0.79까지 다양했는데, Ensemble 결과 점수가 크게 상승하는 것을 보면서 비슷한 점수여도 모델마다 잘하는 것과 못하는 것이 있기 때문에 얻은 결과라고 생각했다.
-