Related to: Machine Learning
General optimizations
Use async data loading
torch.utils.data.DataLoader(dataset, num_workers=num_workers)num_workers=0: 메인 프로세스가 데이터를 디스크에서 동기식으로 로딩합니다.num_workers>0: 여러 프로세스를 사용하여 디스크에서 데이터를 비동기식으로 읽고, 학습과 데이터로딩이 overlapping될 수 있도록 허용합니다. CPU의 데이터 로딩을 빠르게 처리하는 용도로 사용합니다.
Pin memory, transfer data asynchronously
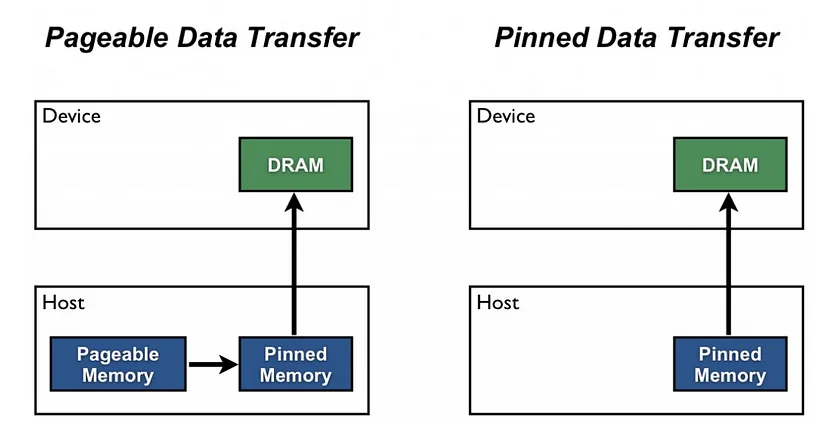
torch.utils.data.DataLoader(dataset, pin_memory=True) batch.to(device, non_blocking=True)- GPU가 pageable host 메모리에서 곧바로 데이터를 가져올 수 없기 때문에, pinned (page-locked) 메모리를 활용
pin_memory=True- 데이터 텐서를 자동으로 pinned 메모리로 가져오기 때문에, 데이터 전송이 빠릅니다.
pin_memory=True, non_blocking=True- pinned 메모리에 있는 데이터에 한해서 GPU로 비동기식으로 데이터를 전송합니다.
- GPU 데이터 전송 이후의 연산이 GPU 데이터를 필요로 하지 않는 경우, 속도 개선 효과를 볼 수 있습니다. 데이터 전송이 모두 완료되기 전에, 기다리지 않고 즉시 연산을 실행하기 때문입니다.
- page-locked memory은 다른 작업에 의해 memory deallocation 되지 않기 때문에, 너무 많은 메모리를 점유하게 될 경우, 다른 데이터가 메모리에 못 올라오는 문제가 생길 수 있습니다.
Efficiently zero-out gradients
model.zero_grad(set_to_none=True)- model.zero_grad() 대신 사용합니다.
- 모든 파라미터마다 memset을 실행하지 않습니다.
- Gradient를 업데이트할 때, “+=” (read+write)이 아닌 “=” (write)를 사용합니다.
Increase batch size
- 배치 크기를 키워서 GPU 메모리를 최대한 활용하는 것이 학습 시간을 단축하는데 큰 도움이 됩니다.
- 배치 크기가 크면, 수렴이 느려질 수 있기 때문에 아래와 같은 방법을 사용해서 보완할 수 있습니다.
- Tune learning rate, tune weight decay
- Add learning rate warm-ups & decay
GPU specific optimizations
Use 16-bit precision
scaler = torch.cuda.amp.GradScaler()
with torch.cuda.amp.autocast(enabled=use_fp16):
output = model(input)
loss = loss_fn(output, target)
if use_fp16:
scaler.scale(loss).backward()
if max_norm is not None:
scaler.unscale_(optimizer)
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm)
scaler.step(optimizer)
scaler.update()Mixed precision training은 FP16, FP32를 같이 사용해서 학습하는 방법입니다. 일반적으로 2단계로 이루어집니다.
- FP16으로 casting.
- FP16 숫자가 0으로 되지 않도록 loss / gradient scaling.: FP16이 나타낼 수 있는 수의 최소 범위 (2²⁴) 보다 숫자가 작아서 0으로 강제 변환하는 문제를 scaling으로 해결.
Mixed precision training을 사용했을 때 다음과 같은 이점이 있습니다.
- FP32으로만 학습할 때와 비슷한 정확도.
- 필요한 메모리 사이즈 감소.
- 학습 시간 감소.Tensor core 를 지원하는 gpu는(e.g. V100) mixed precision training 을 위한 하드웨어 가속을 제공하기 때문에 효과 극대화. V100 기준, 1.5~5배 speedup.
Enable cuDNN autotuner
torch.backends.cudnn.benchmark = True- Nvidia cuDNN은 convolution (CNN)을 계산하기 위해 다양한 알고리즘을 지원하고 있습니다.
- Autotuner는 짧은 benchmark 실행하고, 하드웨어와 input 크기에 최적화된 알고리즘을 선택합니다.
- (주의) 고정된 input 크기일 때만 효과적이고, input 크기가 동적으로 변하면 매번 최적화된 알고리즘을 찾게 되어 시간이 더 오래 걸릴 수도 있습니다.
- (참고) Batch size, input / output size가 최소 64, 이상적으로는 256으로 나뉘어지는 수로 선택하기를 권장합니다.
Avoid unnecessary CPU-GPU synchronization
# don't
.item()
.cuda()
.cpu()
.to(device)
.nonzero()
print(tensor)- 불필요하게 GPU, CPU간 데이터를 전송하는 경우, 성능이 크게 저하됩니다.
- cuda tensor의 operation에 의존하는 경우, 성능이 저하됩니다.e.g.
(cuda_tensor != 0).all()
Construct tensors directly on GPUs
# don't
t = tensor.rand(2,2).cuda()
# do
t = tensor.rand(2,2, device=torch.device('cuda:0'))- Don’t: CPU에 tensor를 생성한 후에 GPU로 전송하기 때문에, 시간이 오래 걸립니다.
- Do: Tensor를 device에 곧바로 생성하는 것을 권장합니다.
Distributed optimizations
Use DistributedDataParallel not DataParallel
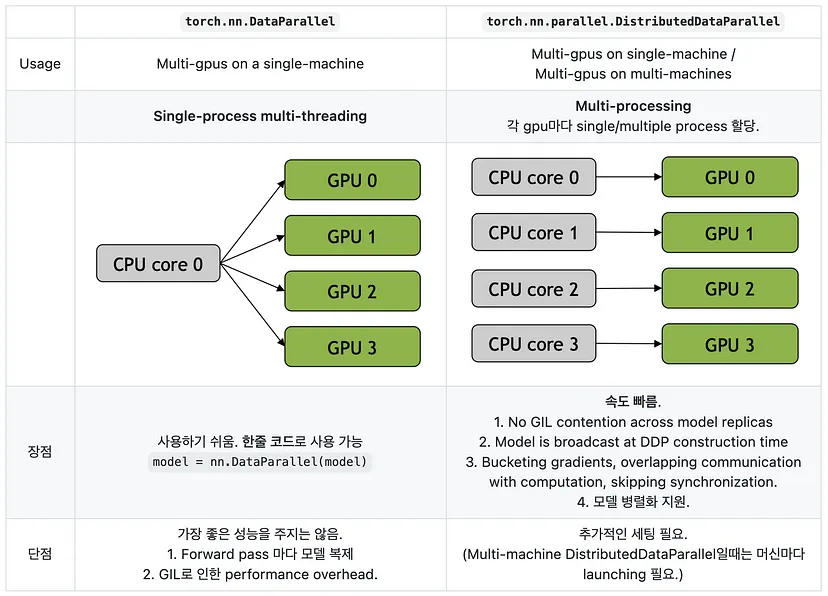
- Spawn processes
nprocs: 현재 머신에서 생성(spawn) 할 프로세스 수(GPU당 하나의 프로세스를 생성하는 경우, nprocs=gpu_num)
torch.multiprocessing.spawn(main_worker, nprocs=args.gpu_num, args=(args,))- Environment variable initialization
MASTER_ADDR: rank 0 머신의 주소.하나의 머신으로 학습할 경우, “127.0.0.1”로 설정.MASTER_PORT: rank 0 머신의 free port.WORLD_SIZE:init_process_group에서 세팅 가능.RANK:init_process_group에서 세팅 가능.- rank 0 머신이 모든 connection을 setup.
os.environ['MASTER_ADDR'] = master_address
os.environ['MASTER_PORT'] = str(master_port)- Initialize process group
backend: nccl (GPU용. backend 가장 빨라서 권장) / gloo (CPU용)init_method: peer process를 어디서/어떻게 찾을 수 있는 지 설정. [참고]환경변수로 MASTER_ADDR, MASTER_PORT 세팅했으면, ‘env://‘로 설정 가능.world_size: 동시에 실행되는 총 애플리케이션 프로세스 수.rank: 모든 프로세스 중 global rank
torch.distributed.init_process_group(backend='nccl',
init_method='env://',
world_size=world_size,
rank=rank)- Distributed Data Parallel
device_ids: 코드가 작동할 GPU device id. 일반적으로 프로세스의 local rank.
model = torch.nn.parallel.DistributedDataParallel(
model,
device_ids=[gpu],
output_device=gpu,
)참조
Top 10 Performance Tuning Practices for Pytorch
Pytorch 모델의 학습 및 추론을 가속화 할 수 있는 10가지 팁을 공유드립니다.
https://medium.com/naver-shopping-dev/top-10-performance-tuning-practices-for-pytorch-e6c510152f76