Related to: MLOps
개요
회사에서 Model을 Serving하는 일을 맡으면서, ONNX를 공부하게 되었습니다. 그러나 변환된 onnx 파일을 사용(인퍼런스) 하기 위해서는 Pytorch, Tensorflow와 같은 Engine이 추가적으로 필요합니다. 따라서 이번에는 onnx 파일을 인퍼런스 할 수 있는 engine 중 하나인 onnx-runtime에 대해서 조사해 보았습니다.
관련 글 : ONNX(Open Neural Network Exchange)
ONNX-Runtime

ONNX Runtime은 오픈 소스 인퍼런스 엔진으로, 딥 러닝 모델의 추론(예측)을 실행하기 위한 플랫폼입니다. ONNX Runtime은 ONNX 모델을 실행하기 위한 최적화된 엔진으로 여러 하드웨어 및 운영 체제에서 딥 러닝 모델을 효율적으로 실행할 수 있습니다.
ONNX-Runtime이 지원하는 환경
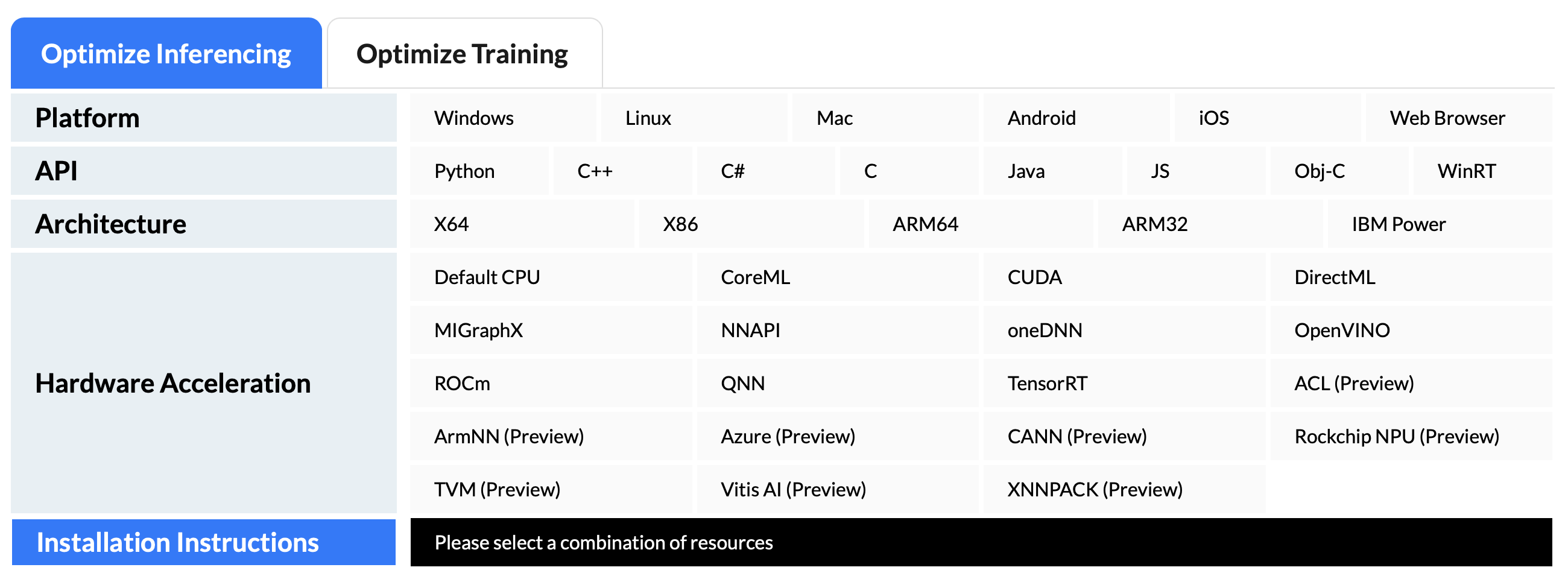
위 이미지는 ONNX Runtime 공식 페이지에 있는 Table을 캡쳐한 것 입니다. Training Tab도 보이지만, 이 글에서는 다루지 않습니다.
위 Table은 상당히 중요한데, 각 Platform 별로 지원되는 API가 다르며 Architecture, HW Acceleration에 따라서도 다릅니다.
따라서 자신이 인퍼런스 할 환경에서 사용이 가능한지 체크할 필요가 있습니다.(예: IOS는 Python이 지원되지 않습니다.)
- Platform은 OS 입니다. Windows부터 시작하여 심지어 web browser까지 매우 다양한 플랫폼을 지원합니다.
- API는 사용할 수 있는 프로그래밍 언어입니다.
- Architecture는 CPU Architecture의 종류입니다.
- 자세한 의미는 이 글을 참조해주세요.
- HW Acceleration은 실제 연산(인퍼런스)을 할 때 사용할 도구입니다. CPU로 할 시, CPU에서 연산을 수행하게 되며 CUDA로 할 시, CUDA를 사용할 수 있는 GPU에서 연산을 수행하게 됩니다.
- 생각보다 매우 많은 가속기가 지원되서 놀랐습니다. 예로, ROCm을 지원하므로(잘 되는지는 모르겠습니다만..) 가지고 있는 device가 nvidia gpu가 아니더라도 Model Inference를 할 수 있습니다.
ONNX-Runtime Project는 누가 관리하고 있을까?
https://github.com/microsoft/onnxruntime
Table을 보면, 절대 개인이 할 수 있는 프로젝트가 아니라는 것이 느껴졌습니다. 그런데도 Open Source라니 누가 관리하고 있는지 궁금해졌습니다.
google에 ‘onnx-runtime github’를 검색하면 바로 나오는데, 바로 MS가 관리하고 있었습니다.
MS를 사랑할 수 밖에 없는 이유가 하나 더 늘었습니다..
ONNX-Runtime 설치 및 사용해보기
ONNX-Runtime의 설치는 사용 환경에 따라 다르겠지만, 이 글은 python에서의 사용을 기준으로 작성되었습니다.
설치는 pip를 이용하여 바로 수행할 수 있습니다. 여기서 주의할 점은 cpu용과 gpu용 패키지가 다르다는 것입니다.
-
CPU Inference용 런타임 설치
pip install onnxruntime -
GPU Inference용 런타임 설치
- gpu용 런타임을 설치했다고 해서 cpu 인퍼런스가 안되는 것은 아니므로 gpu 가속이 가능하신 분들은 고민하지 마시고 gpu 버전을 설치하시면 됩니다.
pip install onnxruntime-gpu -
인퍼런스 코드 예시
import onnxruntime as ort import numpy as np x, y = test_data[0][0], test_data[0][1] providers=['CUDAExecutionProvider', 'CPUExecutionProvider'] ort_sess = ort.InferenceSession('fashion_mnist_model.onnx', providers) outputs = ort_sess.run(None, {'input': x.numpy()}) # Print Result predicted, actual = classes[outputs[0][0].argmax(0)], classes[y] print(f'Predicted: "{predicted}", Actual: "{actual}"')인퍼런스 방법은 매우 간단합니다.
먼저 ‘InferenceSession’이라는 인스턴스를 생성합니다. providers는 연산에 사용할 장치 후보입니다. 만약 CUDA Excution Provider를 사용할 수 없다면 CPU Excution Provider를 사용합니다.
인스턴스의 ‘run’ 메소드에 입력 값을 전달하면 됩니다. 이 때, 첫 번째 값은
None이고 두 번째 값은{’input’: x.numpy()}로 되어 있습니다. None은 출력 값을 선택할 수 있게 해주는 파라미터인데 자세한 내용은 api 문서를 참조하여 주시기 바랍니다. 두 번째 값은 dict 형태로 되어있습니다. 여기서 key에 해당하는 값은 onnx 를 생성할 때 지정했던 입력 파라미터명 입니다. 그리고 value에 해당하는 값은 실제 입력 값 입니다.torch를 사용해보신 분들은 ~.to(device)가 없어서 의아해 하실 수 있습니다. onnx-runtime는 위와 같이 입력해도 내부에서 알아서 gpu로 데이터를 변환해줍니다.
그리고 outputs 또한 마찬가지로 연산을 수행한 장치의 데이터가 아닌, 우리가 바로 다루고 처리할 수 있는 ram에 존재하는 데이터로 돌려줍니다.
-
성능 최적화 - I/O Binding
-
위 방식는 처음엔 편리하지만, 최적화와 고속처리가 필요 할 때 문제가 될 수 있습니다.(메모리 관련 처리가 어떻게 되고 있는지 불확실하고, 더 low level에서의 제어하고 싶을 때가 있습니다) 이 부분은 문서에서 다음과 같이 말하고 있습니다.
CPU가 아닌 실행 공급자로 작업할 때는 그래프를 실행하기 전에(
Run()호출) 대상 장치에 입력(및/또는 출력)을 정렬하는 것이 가장 효율적입니다(사용된 실행 공급자에 의해 추상화됨). 입력이 대상 장치에 복사되지 않으면 ORT는Run()호출의 일부로 CPU에서 입력을 복사합니다. 마찬가지로 출력이 디바이스에 미리 할당되지 않은 경우 ORT는 출력이 CPU에서 요청된 것으로 가정하고Run()호출의 마지막 단계로 디바이스에서 복사합니다. 이것은 그래프의 실행 시간을 잠식하여 대부분의 시간이 이러한 복사본에 소비될 때 ORT가 느리다고 생각하도록 사용자를 오도합니다.이 문제를 해결하기 위해 IOBinding이라는 개념을 도입했습니다. 핵심 아이디어는
Run()을 호출하기 전에 입력을 장치에 복사하고 출력을 장치에 미리 할당하도록 정렬하는 것입니다. IOBinding은 모든 언어 바인딩에서 사용할 수 있습니다. -
요약하자면 미리 메모리를 할당할 수 있다는 것을 의미합니다.
-
더 정확한 설명과 사용예시는 이 문서를 참조하시면 됩니다.
-
마치며
위 onnx-runtime을 지원하는 환경에 대한 테이블을 보고 든 생각은 적어도 Model Inference에 있어서는 Python을 고집 할 필요가 없지 않을까? 라는 생각이었습니다. 특히 제가 하고있는 일은 고속처리가 필요해서 컴퓨팅 자원을 최대한 활용할 수 있어야 하기 때문에 python이라는 언어로는 한계를 느끼고 있습니다.
다음에 기회가 되면 다른 언어에서 문제없이 잘 인퍼런스 되는지 확인해보려고 합니다.