Related to: Deep Learning
VGGNet이란?
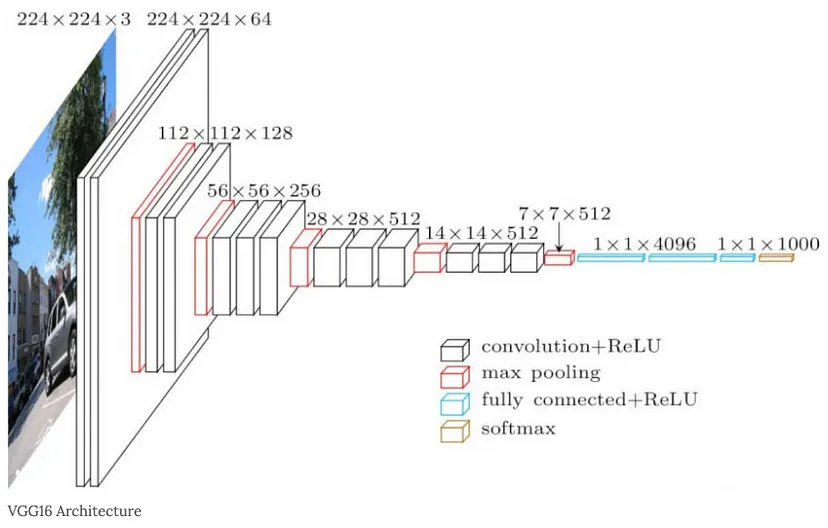
VGGNet은 딥러닝 모델에서 사용되는 이미지 인식 알고리즘으로, 2014년 옥스퍼드 대학교의 Visual Geometry Group(VGG)에서 개발한 합성곱 신경망입니다. VGGNet은 CNN Layer 및 Pooling Layer와 FC Layer로 이루어져 있습니다.
CNN Layer는 이미지의 특징을 추출하는 데 사용되며 FC Layer는 Classification에 사용됩니다.
VGGNet의 특정
VGGNet은 이전까지 발전해왔던 모델들과는 다른 부분(depth)에 초점을 맞춘 모델입니다.
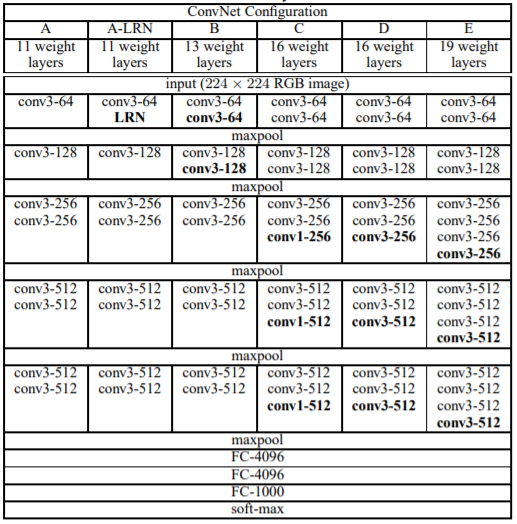
-
매우 작은 커널 사이즈(3x3)을 사용
- VGG 모델 이전에 Convolutional Network를 활용하여 이미지 분류에서 좋은 성과를 보였던 모델들은 비교적 큰 Receptive Field를 갖는 11x11필터나 7x7 필터를 사용했습니다.
그러나 VGG 모델은 오직 3x3 크기의 작은 필터만 사용했음에도 이미지 분류 정확도를 비약적으로 개선시켰습니다.
여기서 얻을 수 있는 통찰은 Stride가 1일 때, 3차례의 3x3 Conv 필터링을 반복한 특징맵은 한 픽셀이 원본 이미지의 7x7 Receptive field의 효과를 볼 수 있다 입니다.- 7x7 필터를 이용해 이미지에 대해 한 번 Convolution을 수행한 것과 3x3 필터로 세 번 Convolution을 수행한 것의 차이
- 비선형성 증가 : 3x3을 여러번 하는 것이 Activation Function를 여러번 사용됨
- 파라미터 수 감소 : 7x7x1 = 49 vs 3x3x3 = 27
- 7x7 필터를 이용해 이미지에 대해 한 번 Convolution을 수행한 것과 3x3 필터로 세 번 Convolution을 수행한 것의 차이
- VGG 모델 이전에 Convolutional Network를 활용하여 이미지 분류에서 좋은 성과를 보였던 모델들은 비교적 큰 Receptive Field를 갖는 11x11필터나 7x7 필터를 사용했습니다.
참조
https://arxiv.org/pdf/1409.1556.pdf