Related to: Deep Learning
등장 배경
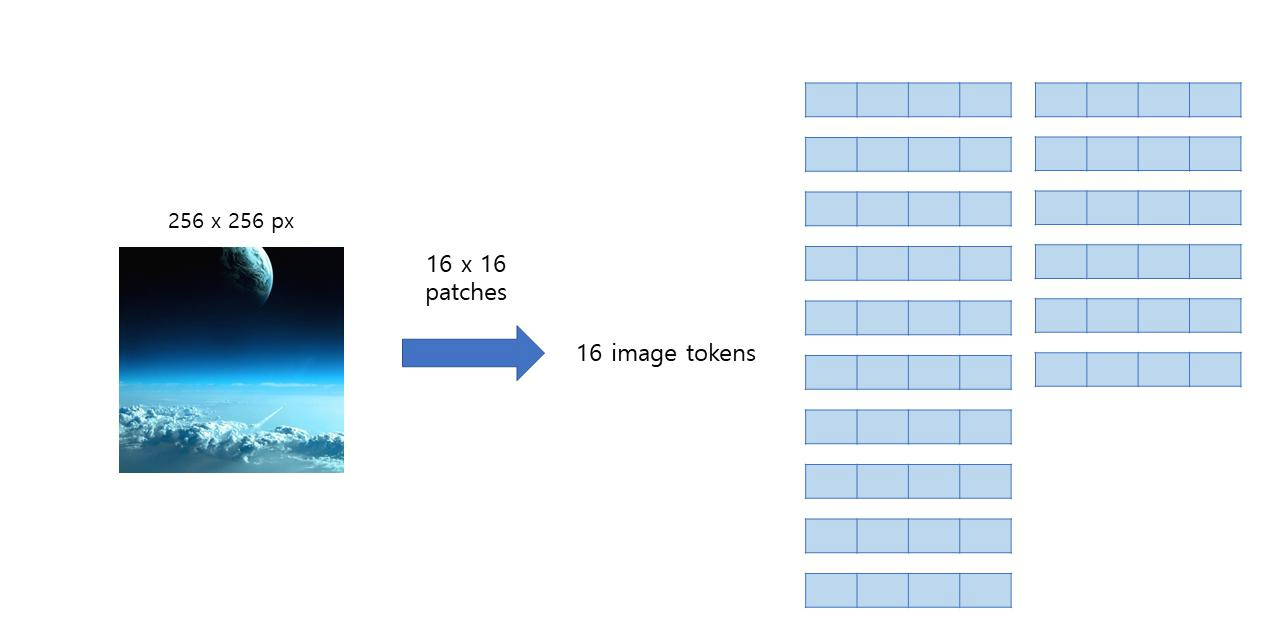
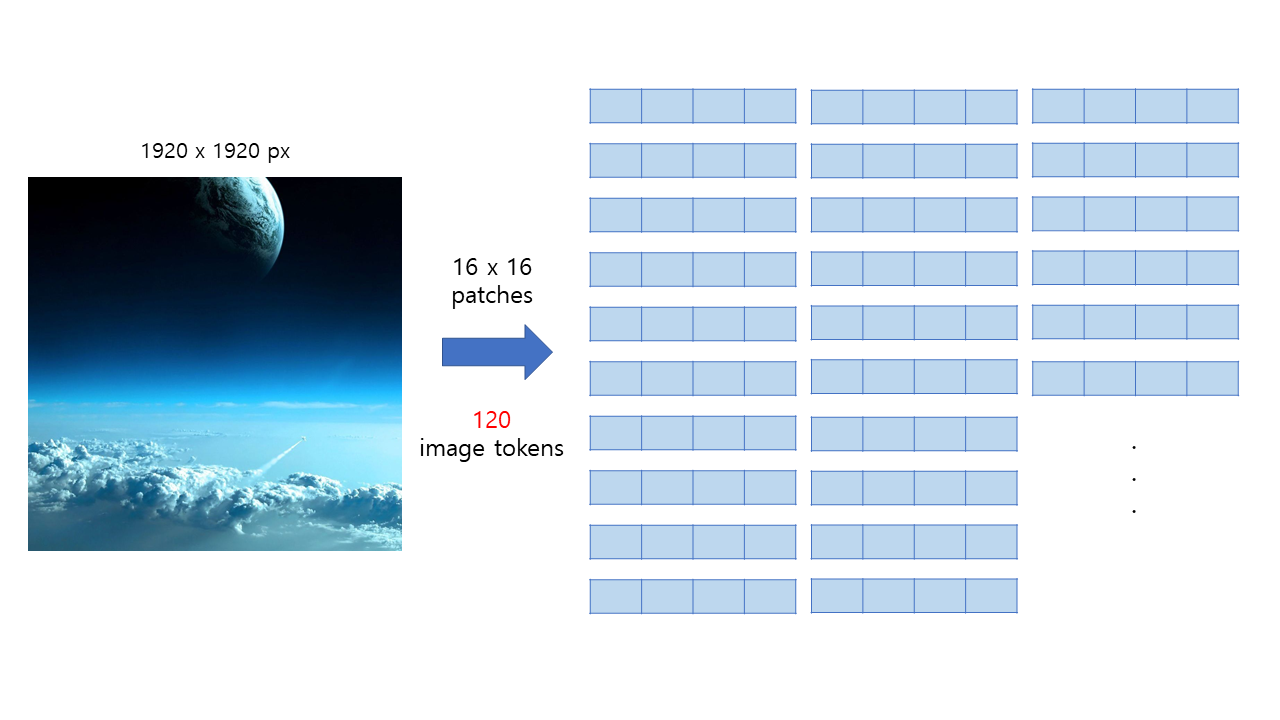
Transformer based approach의 문제점
- computational complexity on high-resolution images
- 이미지의 해상도, 픽셀이 늘어나면 늘어날수록 모든 patch의 조합에 대해 self-attention을 수행하는 것은 불가능해짐
Swin Transformer
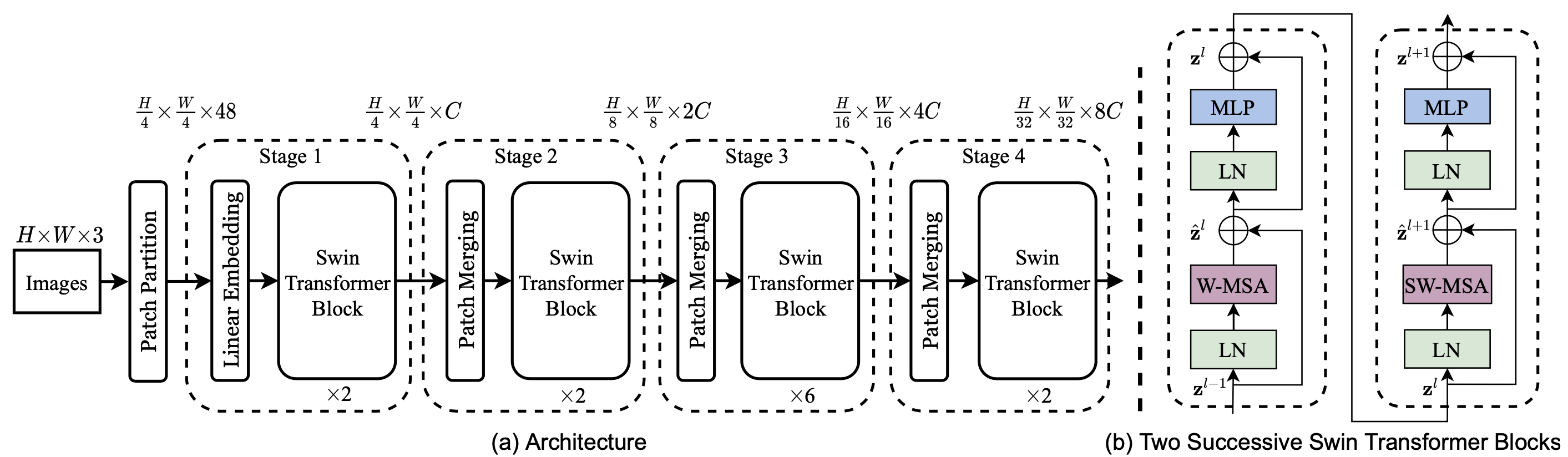
Swin Transformer에서는 hierarchical feature map을 구성함으로써 이미지 크기에 대해 linear complexity를 가질 수 있도록 고안된 아키텍처를 제시합니다.
이것은 다양한 비전 분야의 작업에 있어 general-purpose backbone으로 적합하게 만들며, 단일 해상도의 feature map을 만들고 quadratic complexity를 갖는 이전의 트랜스포머 기반 아키텍처와 차이점을 가집니다.
Swin Transformer Block은 Window 기반의 W-MSA와 SW-MSA 모듈로 이루어지며, 각각의 MSA 모듈을 포함한 2개의 연속적인 트랜스포머로 하나의 Swin block이 형성됩니다.
그 이의의 부분(Layer Normalization, MLP, GELU 등)은 ViT와 같습니다.
Shifted Windows
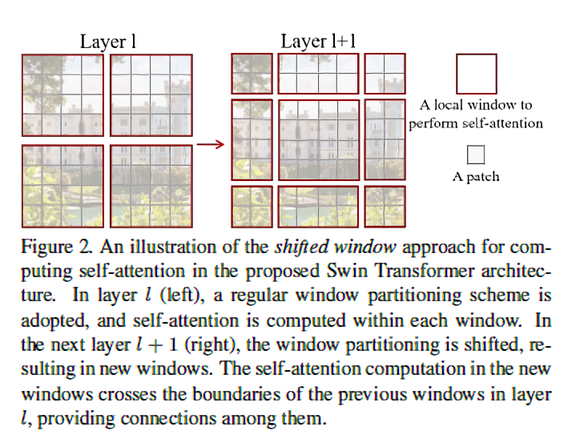
각 Block에서 Patch들을 Window로 분할하는 것을 두 가지 방식으로 진행합니다.
- W-MSA(window based multi-head self attention)
- feature map을 M개의 window로 나누는 것 (regular - 위 그림에서 왼쪽)
- SW-MSA(shifted window based multi-head self attention)
- W-MSA 모듈에서 발생한 패치로부터([M/2, M/2])칸 떨어진 patch에서 window 분할
Self-attention방식
- Window들 내부에서만 patch끼리의 self-attention을 계산
- computational complexity의 한계를 극복하기위한 방안
- Window : M개의 인접한 patch들로 구성되어 있는 patch set
SW-MSA의 문제
- W-MSA에서 (H/M) * (W/M)이였던 Window 수가 SW-MSA 모듈에서는 (H/M + 1) * (W/M + 1)로 달라지게 됩니다.
- ex) W-MSA에서 2x2였던 Window 수가 SW-MSA에서는 3x3이 됩니다.
저자는 SW-MSA의 문제에 대해서는 두 가지 Approach를 제시합니다.
-
Naive Solution
- 작아진 window들에 padding을 두어 크기를 다시 으로 맞춰주고, attention을 계산할 때 padding된 값들을 마스킹
- 연산량의 증가(2x2→3x3 , 2.25배 더 상승)
-
Cyclic-shift(Efficient Batch Computation for Shifted Configuration)
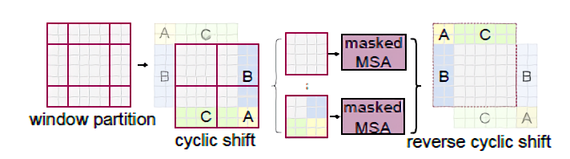
- 왼쪽 상단을 향해 cyclic하게 회전하기
- Batch Window는 Feature map에서 인접하지 않은 여러 하위 window로 구성될 수 있음
- self-attention 계산을 각 하위 window 내에서 제한하기 위해 마스킹 메커니즘 사용
- Batch Window 개수가 regular window partitioning 때와 동일하게 유지되므로 효율적(low latency)
Hierarchical Stages
Hierarchical Stages
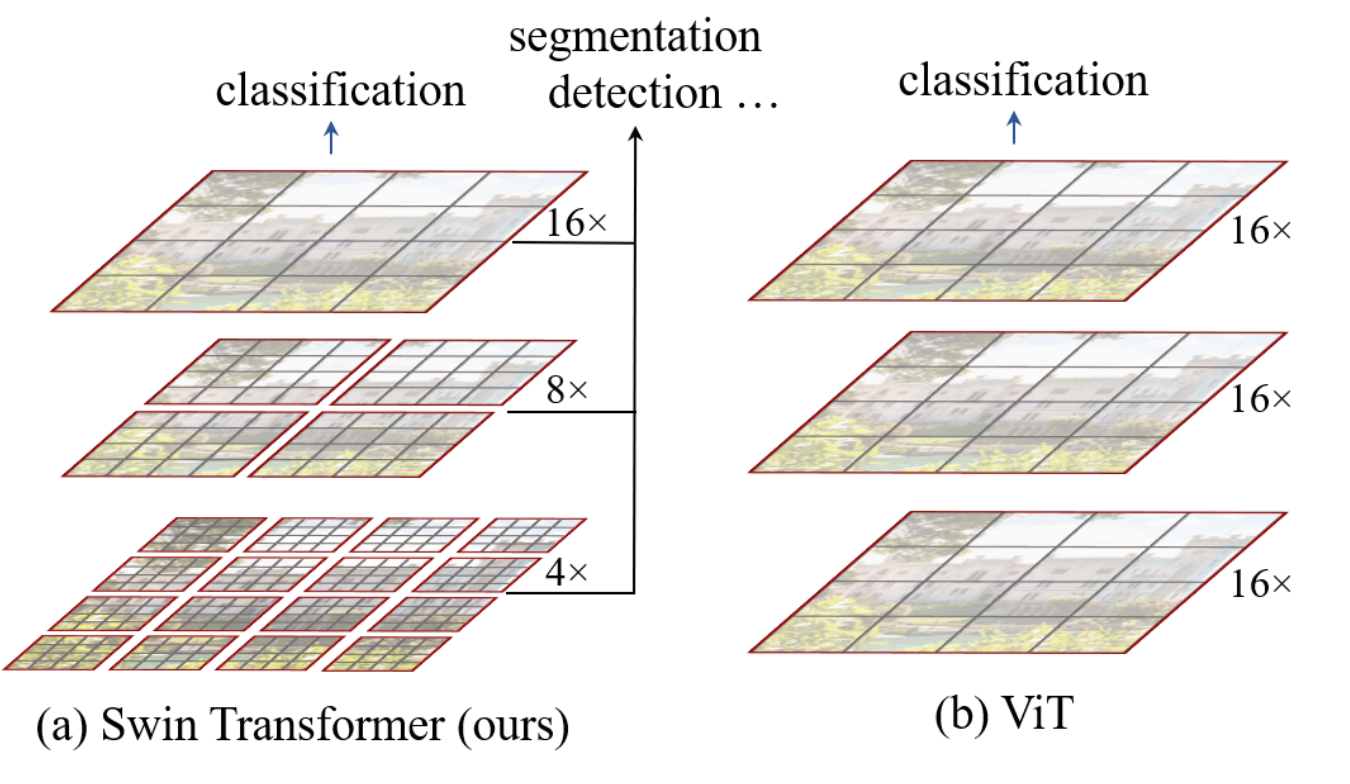
patch들을 합치며 계층적인 구조로 각 단계마다 representation을 갖기 때문에 다양한 크기의 entity를 다루어야 하는 비전 분야에서 좋은 성능을 낼 수 있음
- ViT vs Swin
- ViT : image→patch
- 이미지를 작은 patch들로 쪼개는 방식
- ViT의 Patch size : 16 x 16
- Swin : patch→proportion of image→image
- ViT보다 더 작은 단위의 patch로부터 시작해서 점점 patch들을 merge
- Swin의 Patch size : 4 x 4
- ViT : image→patch
Relative position bias
- Swin은 position embedding이 없으며, 이를 대신하여 Attention 시 Relative position bias(B)를 추가했습니다.
- 저자는 bias 항이 없거나 absolute position embedding을 사용했을 때보다 상당한 모델 성능의 향상을 보였다고 합니다.
Patch Merging
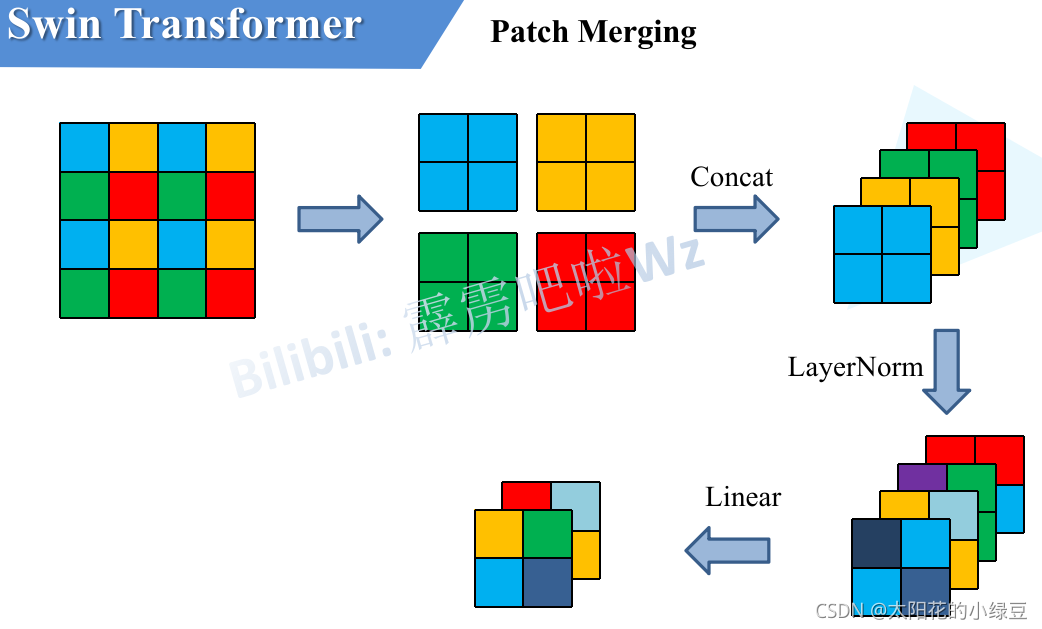
- 인접한(2×2)=4개의 patch들끼리 결합하여 하나의 큰 patch를 새롭게 만듭니다.
- patch를 합치는 과정에서 차원이 4C로 늘어나기 때문에 linear layer를 통과하여 2C로 조정합니다(feature transformation).
Inference Sequence
- Input
- Patch Partition
- 이미지를 Patch 단위로 나누기
- H x W x 3 → (H/4) x (H/4) x 48
- 48 : 3 x M → 3 x 16
- Patch Partition
- Stage 1
- Linear embedding
- (H/4) × (W/4) × 48 → (H/4) × (W/4) × C
- Swin Transformer block
- (H/4) × (W/4) × C → (H/4) × (W/4) × C
- Linear embedding
- Stage 2
- Patch Merging
- (H/4) × (W/4) × C → (H/8) × (W/8) × 4C
- (H/4) × (W/4) × 4C → (H/8) × (W/8) × 2C
- Swin Transformer block
- (H/4) × (W/4) × 2C → (H/8) × (W/8) × 2C
- Patch Merging
- Stage 3
- Patch Merging
- (H/8) × (W/8) × 2C → (H/16) × (W/16) × 8C
- (H/16) × (W/16) × 8C → (H/16) × (W/16) × 4C
- Swin Transformer block
- (H/16) × (W/16) × 8C → (H/16) × (W/16) × 4C
- Patch Merging
- Stage 4
- Patch Merging
- (H/16) × (W/16) × 8C → (H/32) × (W/32) × 16C
- (H/32) × (W/32) × 16C → (H/32) × (W/32) × 8C
- Swin Transformer block
- (H/32) × (W/32) × 8C → (H/32) × (W/32) × 8C
- Patch Merging