Related to: Deep Learning
SSD(Single Shot Multibox Detector)
Yolo의 문제점은 입력 이미지를 7x7 크기의 그리드로 나누고, 각 그리드 별로 Bounding Box Prediction을 진행하기 때문에 그리드 크기보다 작은 물체를 잡아내지 못하는 문제가 있었습니다.
그리고 신경망을 모두 통과하면서 컨볼루션과 풀링을 거쳐 coarse한 정보만 남은 마지막 단 피쳐맵만 사용하기 때문에 정확도가 하락하는 한계가 있었습니다.
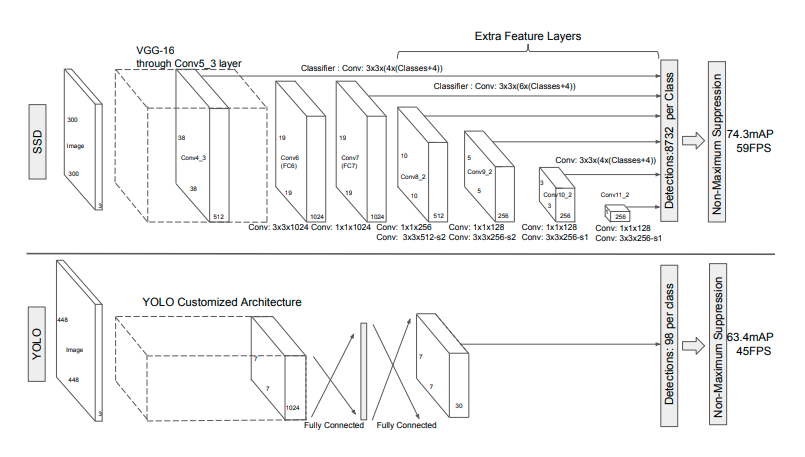
SSD는 이를 해결하고자 앞단 CNN Feature Map을 끌어와 사용하여 Detail을 잡아내고 Faster RCNN의 Anchor 개념을 가져와서 다양한 형태의 Object들도 감지하려고 시도했습니다.
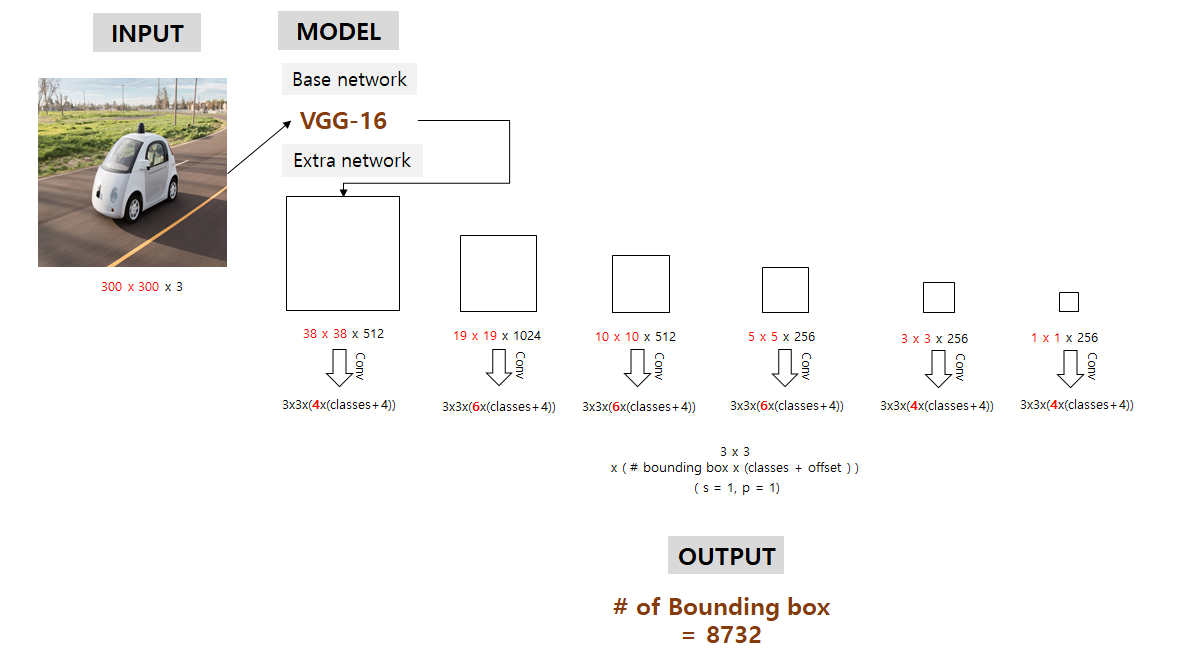
yolo v1은 7x7 grid로 2개의 Bounding Box를 예측했습니다. 하지만 SSD의 Feature Map을 보면 매우 다양한 dimension으로 이루어져 있는 것을 알 수 있습니다.
- Feature Map 1 : 38 x 38 x 512 → 38 x 38 x B개의 Bounding Box 예측
- Feature Map 2 : 19 x 19 x 1024 → 19 x 19 x B개의 Bounding Box 예측
- Feature Map 3 : 10 x 10 x 512 → 10 x 10 x B개의 Bounding Box 예측
- Feature Map 4 : 5 x 5 x 256 → 5 x 5 x B개의 Bounding Box 예측
- Feature Map 5 : 3 x 3 x 256 → 3 x 3 x B개의 Bounding Box 예측
- Feature Map 6 : 1 x 1 x 256 → 1 x 1 x B개의 Bounding Box 예측
또한 yolo v1에서는 Bounding Box와 별개로 Grid의 Class를 예측했다면, SSD는 Bonding Box 별로 Class를 예측한다는 것을 Conv Filter Size 공식을 보면 알 수 있습니다.
Conv Filter Size = 3 x 3 x (B x (C + offset))
- stride = 1, padding = 1
- B : Bounding Box 개수
- C : Class 개수
- offset : Bounding Box의 center x, center y, width, height
Loss
-
Loss Function
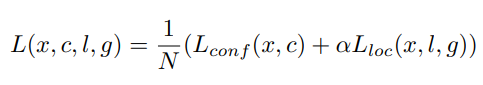
-
Localization Loss
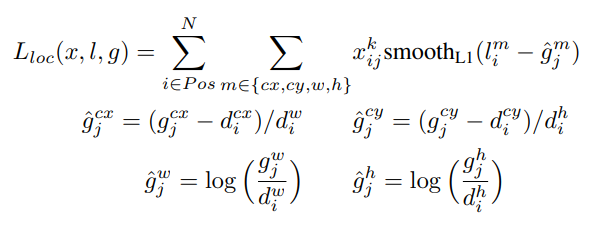
-
Confidence Loss
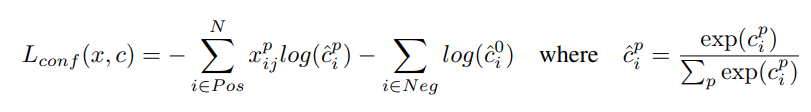
참조
SSD: Single Shot MultiBox Detector
We present a method for detecting objects in images using a single deep neural network.
https://arxiv.org/abs/1512.02325