Related to: Deep Learning
Batch normalization(Batch Norm)
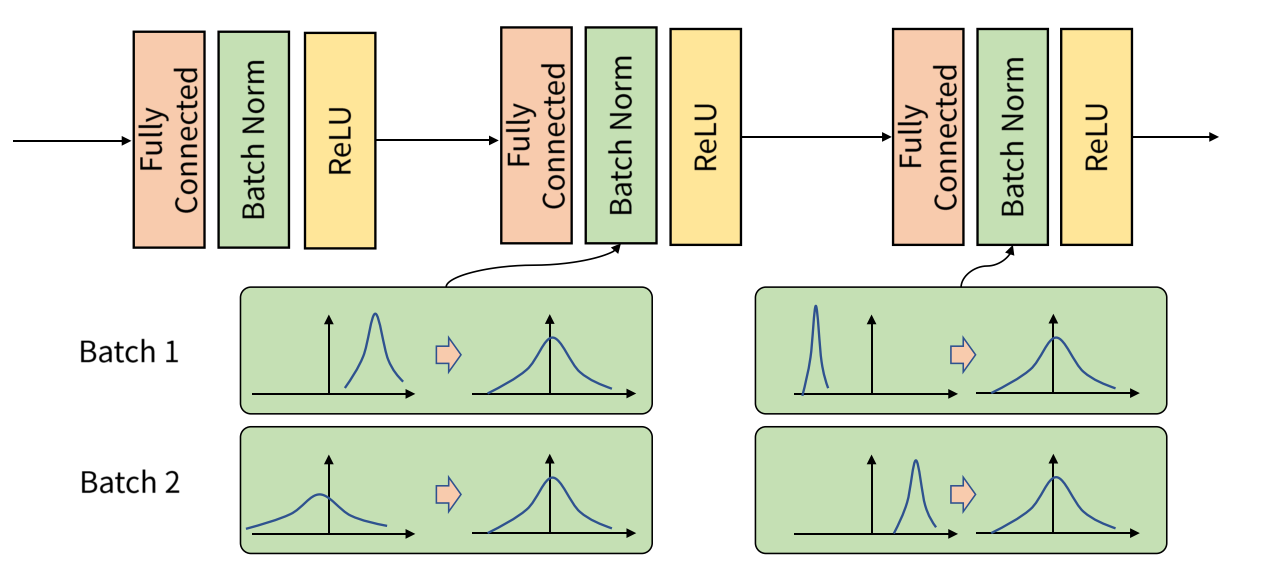
batch normalization은 학습 과정에서 각 배치 단위 별로 데이터가 다양한 분포를 가지더라도 각 배치별로 평균과 분산을 이용해 정규화하는 것을 뜻합니다.
- gradient descent에서는 gradient를 한번 업데이트 하기 위하여 모든 학습 데이터를 사용합니다.
- 그러나 대용량의 데이터를 한번에 처리하지 못하기 때문에 데이터를 batch 단위로 나눠서 학습을 하는 방법을 사용하는 것이 일반적이며, SGD 등을 사용합니다.
- Batch 단위로 학습을 하게 되면 Internal Covariant Shift 문제가 발생할 수 있으며 Batch Normalization으로 이를 해결할 수 있습니다.
Batch normalization - 학습단계
-
학습 단계의 BN을 구하기 위하여 사용된 평균과 분산을 구할 때에는 배치별로 계산
되어야 의미가 있습니다. -
batch normalization은 activation function 앞에 적용됩니다.
-
batch normalization을 적용하면 weight의 값이 평균이 0, 분산이 1인 상태로 분포가 되어지는데, 이 상태에서 ReLU가 activation으로 적용되면 전체 분포에서 음수에 해당하는 (1/2 비율) 부분이 0이 되어버립니다. 기껏 정규화를 했는데 의미가 없어져 버리게 됩니다.
-
따라서 γ,β가 정규화 값에 곱해지고 더해져서 ReLU가 적용되더라도 기존의 음수 부분이 모두 0으로 되지 않도록 방지해 주고 있습니다. 물론 이 값은 학습을 통해서 효율적인 결과를 내기 위한 값으로 찾아갑니다.
Batch normalization - 추론단계
추론 과정에서는 framework에서 옵션을 지정하여 평균과 분산을 moving average/variance
를 사용하도록 해야합니다.
- 추론 과정에서는
BN에 적용할 평균과 분산에 고정값을 사용합니다. - 추론 시에는 배치 단위로 데이터를 넣지 않기 때문에, 학습 단계에서 배치 단위의 평균/분산을 저장해 놓고 테스트 시에는 평균/분산을 사용합니다.
- 고정된 평균과 분산은 학습 과정에서 이동 평균(moving average) 또는 지수 평균(exponential average)을 통하여 계산한 값입니다.
- 학습 하였을 때의 최근 N개에 대한 평균 값을 고정값으로 사용하는 것입니다.
- 이동 평균을 하면 N개 이전의 평균과 분산은 미반영 되지만 지수 평균을 사용하면 전체 데이터가 반영됩니다.
Internal Covariant Shift
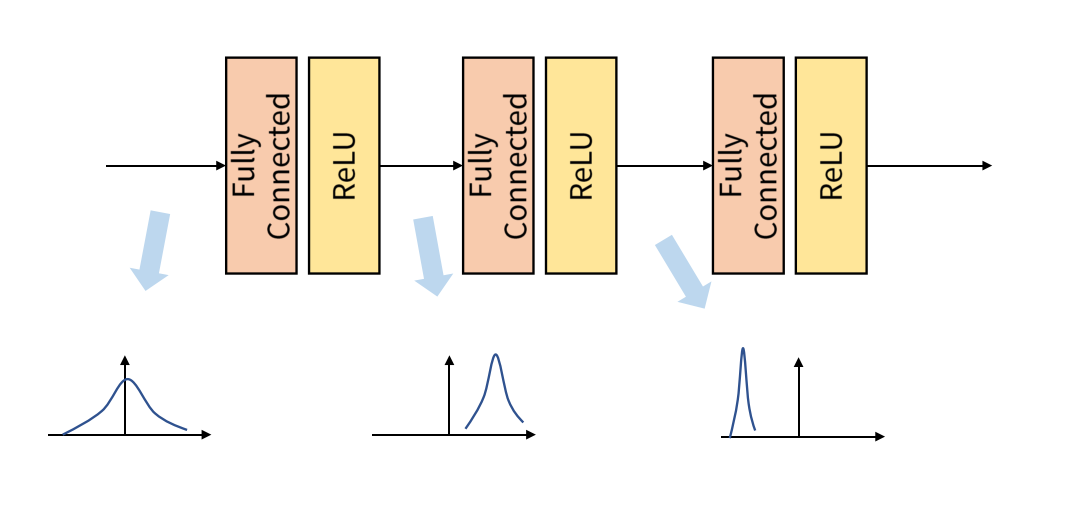
Internal Covariant Shift는 학습 과정에서 계층 별로 입력의 데이터 분포가 달라지는 현상입니다.
이와 유사하게 Batch 단위로 학습을 하게 되면 Batch 단위간에 데이터 분포의 차이가 발생할 수 있습니다.