Related to: Deep Learning
Pix2Pix란?
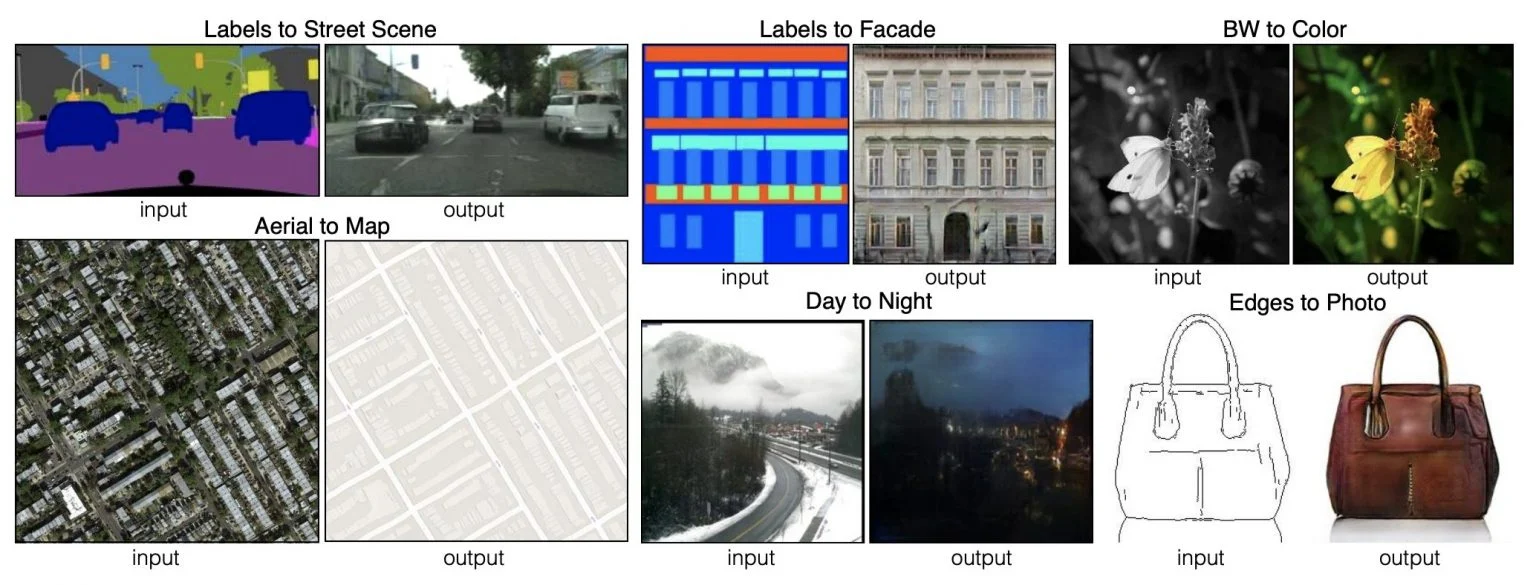
Pix2Pix는 image를 image로 변환하도록 generator을 학습합니다. 예를 들어, generator의 입력값으로 스케치 그림을 입력하면 완성된 그림이 나오도록 학습할 수 있습니다.
Pix2Pix의 특징
-
Loss에 Ground-truth와의 차이도 반영
- 기존의 GAN과 다르게 Loss에 GT와의 차이를 반영합니다.
-
Noise Vector를 사용하지 않음
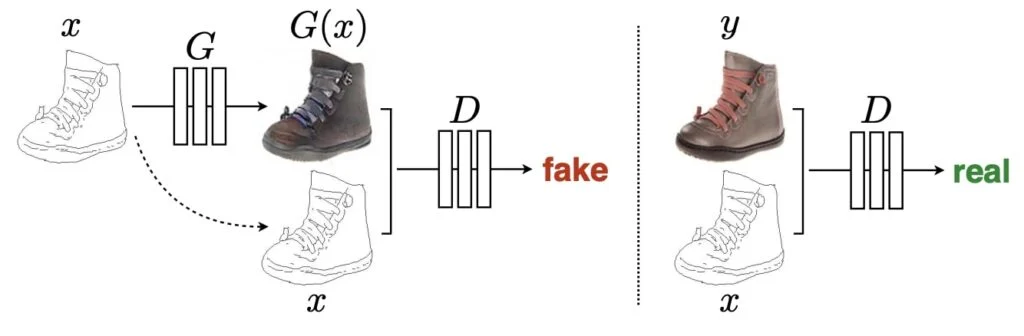
- Pix2Pix GAN은 CGAN의 아이디어를 확장시켜서, Paired Image-to-Image translation을 추가한 것입니다. Pix2Pix GAN은 generator에서 노이즈 벡터의 개념을 사용하지 않습니다.
- 이미지가 generator의 입력으로 들어가고, translated된 이미지가 출력됩니다.
- Discriminator는 conditional discriminator로 real/fake 이미지와 condition을 입력으로 받습니다. 역할은 기존처럼 real/fake를 판단하는 것입니다.
- Pix2Pix GAN의 최종적인 목표는 다른 GANs과 동일합니다. Discriminator를 속이는 이미지들을 Generator가 생성하게 만드는 것입니다.
-
UNet Generator 사용
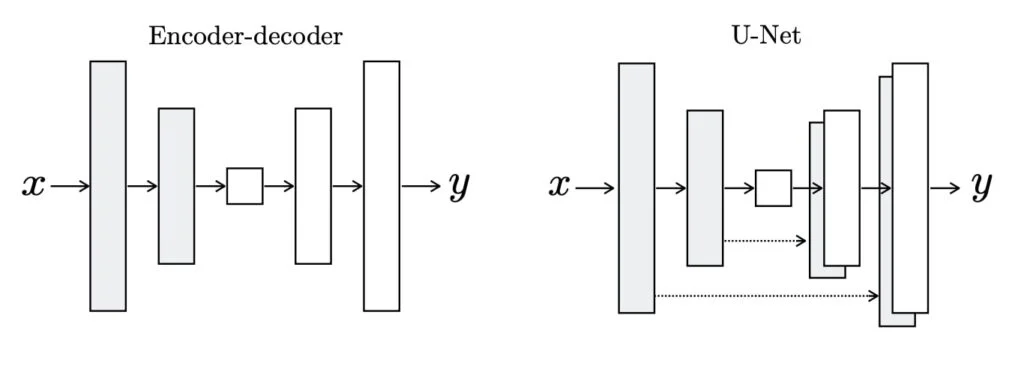
- 초창기 GANs 아키텍쳐처럼 노이즈 벡터를 입력으로 받는것이 아니라, 이미지들을 입력으로 받아서 마치 AutoEncoder 형태로 generator를 구성합니다.
- 따라서 Generator에는 encoder,decoder networks가 있습니다. Pix2Pix는 UNET을 Generator로 사용하게 되는데, 이것은 mirrored layers 사이에 skip-connections이 있다는 특징이 있습니다.
-
PatchGAN Discriminator
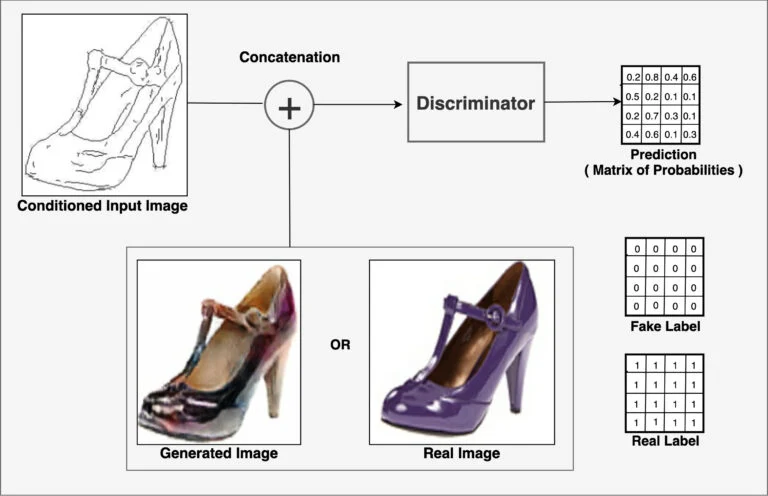
- Pix2Pix는 PatchGAN이라 불리는 Discriminator를 사용하는데, output으로 확률값(scalar)을 내놓는 대신에, 영역의 Tensor값들을 반환합니다. 즉, 입력 이미지에 대해서 discriminator는 행렬값을 반환하게 되는데, 이미지 전체를 한번에 판단하는 것보다, 세부 영역들에 대해 구분한 값을 반환하게 됩니다.
Loss Function
-
Discriminator
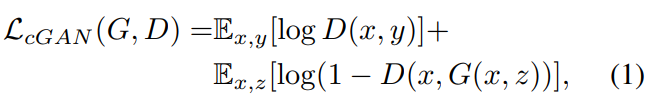
- 이전의 GANs모델과 같은 loss함수를 사용합니다. 즉, real과 fake를 구별하기 위해, negative log-likelihood를 최소화하는 것이 목표입니다. 또한 저자는 Generator보다 빨리 학습하는 것을 방지하기 위해 2로 나누어 주었습니다.
-
Generator
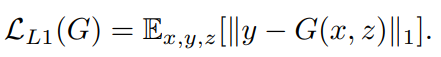
- 실제 라벨값들은 Generator를 학습시키는데 사용됩니다.
- 또한 추가적인 L1 loss 항을 본 논문에서는 더해주었는데, error를 최소화하는데 사용됩니다. L1 loss값들은 실제 정답과 예측값들 간의 차이의 절댓값이며, L1 규제를 통해서 translated된 이미지가 target하고 유사하지 않는 경우 penelty를 부여하는 역할을 합니다.
- L1을 사용하는 이유는 저자가 실험적으로 기존의 다른 Loss(ex: L2)보다 덜 blurry한 이미지를 얻었기 때문입니다.
-
Total Loss
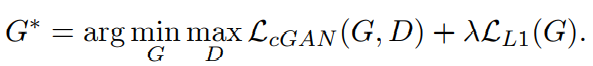
참조
https://deep-learning-study.tistory.com/645
https://velog.io/@wilko97/논문실습-Pix2Pix