Related to: Deep Learning
Object Detection History(2001~2022)
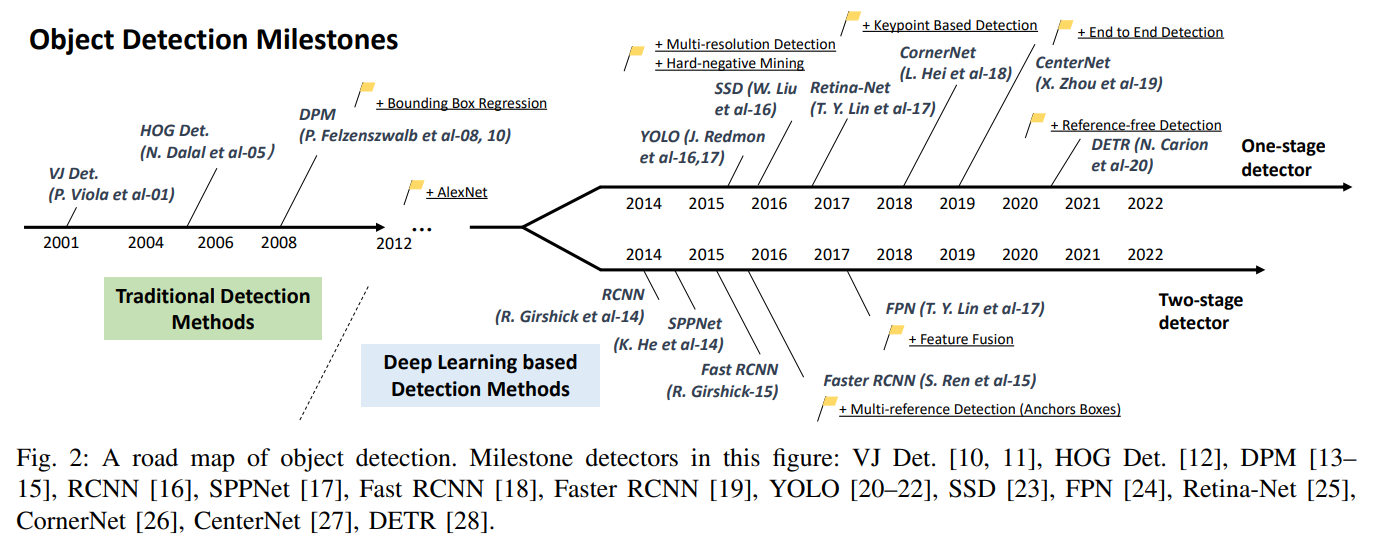
-
RCNN
- 선택적 검색을 통해 일련의 객체 Proposal(객체 후보 상자)을 추출
- Proposal은 고정된 크기의 이미지로 재조정되고 ImageNet(예: AlexNet)에서 사전 훈련된 CNN 모델로 Feature 추출
- Linear SVM 분류기로 각 영역 내 객체의 존재를 예측하고 객체 범주를 인식하는 데 사용
- 한 이미지에서 2000개 이상의 Proposal이 있고, 이를 모두 고정 크기로 조절한 뒤 CNN을 통과해야 하기 때문에 매우 느린 속도를 보임
-
SPPNet
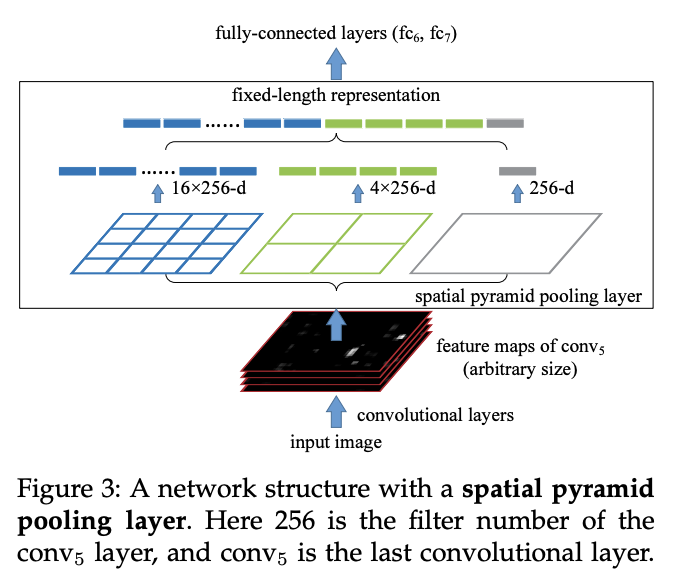
- Spatial Pyramid Pooling Layer 구조를 제안, 입력 이미지 크기와 상관 없이 fixed-length represntation(고정 크기의 vector) 생성 가능
- Feature Map에서 21 bin = [4x4, 2x2, 1x1] 등으로 고정 크기로 Feature를 Max Pooling 하는 Layer
- FC Layer 때문에 수행하던 crop / warp의 필요성이 사라져 속도 향상
- (RCNN 대비 20배 빠른 속도)
- Spatial Pyramid Pooling Layer 구조를 제안, 입력 이미지 크기와 상관 없이 fixed-length represntation(고정 크기의 vector) 생성 가능
-
Fast RCNN
- RCNN이 selective search로 찾아낸 모든 RoI에 대해서 CNN inference를 하는 문제를 CNN inference를 전체 이미지에 대하여 1회만 수행하고, 이 피쳐맵을 공유하는 방식으로 해결
- ROI Pooling 제안
- 더 이상 SVM을 사용하지 않고 end-to-end 훈련이 가능해짐
- R-CNN보다 200배 이상 빠른 Inference 속도
-
FPN
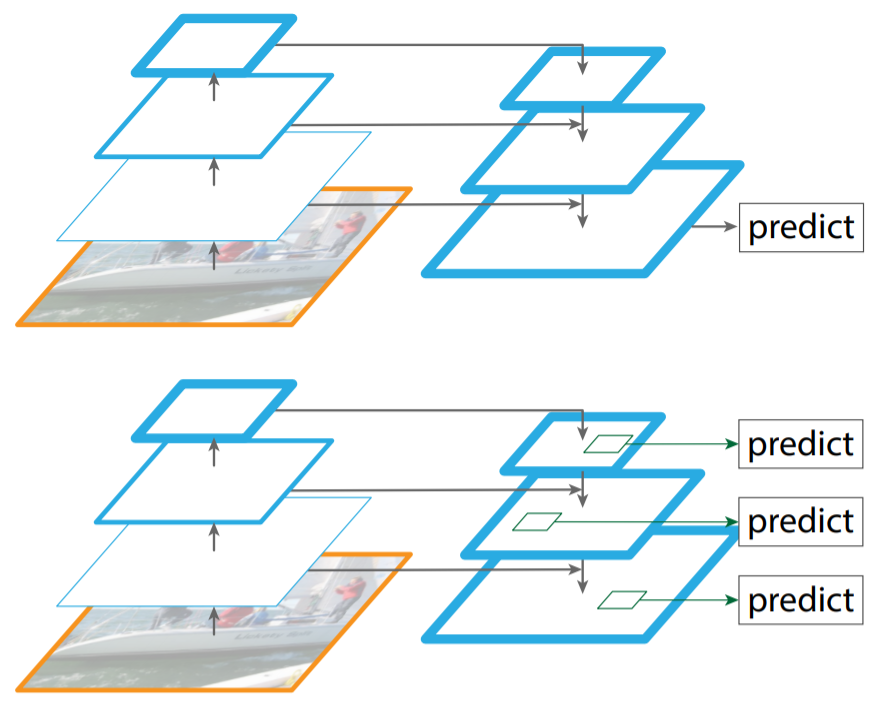
- Pyramid Networks 제안, CNN은 순방향 전파를 통해 자연적으로 피쳐 피라미드를 형성하기 때문에 FPN은 다양한 규모의 객체를 감지하는 데 큰 발전을 보임
- 1x1 conv 연산을 적용하여 모두 256 channel을 가지도록 조정하며 Up Sampling을 통해 width, height를 맞춰 Lateral connections 과정을 통해 pyramid level 바로 아래 있는 feature map과 element-wise addition 연산을 수행
-
YOLO(You Only Look Once)
- 최초의 1 Stage Detector
- 매우 큰 inference 속도 향상
- 일부 작은 물체의 경우 2 Stage Detector에 비해 위치 파악 정확도가 떨어짐
-
SSD(Single Shot MultiBox Detector)
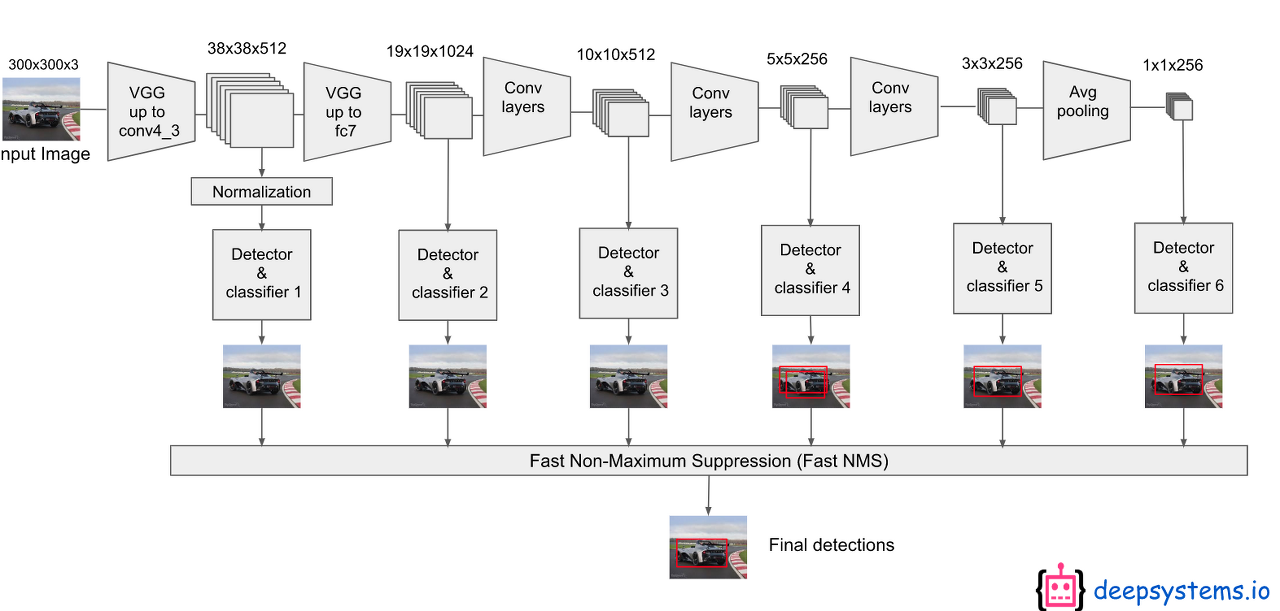
- 앞단 CNN Feature Map을 끌어와 사용하여 Detail을 잡아내고, Faster RCNN의 anchor 개념을 가져와 다양한 형태의 Object들도 잡아낼 수 있도록 구조 설계
- yolo의 약점이었던 일부 작은 물체에 대해 검출 정확도를 크게 향상, inference 속도 향상
-
RetinaNet
- 1 Stage Detector들이 2 Stage Detector들에 비해 정확도가 떨어지는 이유를 탐구, Dence Detector 훈련 중 발생하는 전경과 배경간의 극단적인 Class Imbalance가 원인임을 발견
- Cross Entropy Loss를 수정하여 Focal Loss라는 새로운 손실 함수 제안
- 1 Stage Detector가 매우 높은 검출 속도를 유지하면서 2 Stage Detector와 비슷한 정확도를 달성할 수 있었음
-
CornerNet
- 앵커를 사용하지 않고 Corner를 예측을 수행
- 이전 연구들은 앵커 박스를 사용하며 Bounding box regression, Classification을 수행했으나 Detection 된 객체는 수, 위치, 크기, 비율 등의 측면에서 자주 변형이 나타남
- CNN을 통해서 top-left, bottom-right corner를 위한 각각의 heat map을 예측
- Corner Grouping을 위한 Embedding Vector 생성, Vector간 distance를 기준으로 Grouping 수행
- 작은 해상도의 heat map에서 원본 이미지로 복원하는 과정에서 위치가 부정확해지는 것을 막기 위한 offset 예측 수행
- 당시 대부분의 1단계 검출기보다 높은 성능 달성(COCO mAP@.5=57.8%)
- 앵커를 사용하지 않고 Corner를 예측을 수행
-
CenterNet
- keypoint-based detection 패러다임을 따르지만 CornerNet에서 사용하던 keypoint grouping 방식과 NMS 등의 비용이 높은 post process를 제거한 End-to-End Network을 제안
- Object를 Single Point로 간주하고(Object Center) 해당 Point를 기준으로 하는 크기, 방향, 위치를 Regression
- 높은 성능 달성(COCO mAP@.5=61.1%)
-
DETR(DEtection TRansformer)
- Object Detection을 Set Prediction 문제로 보고 Transformer를 사용한 end-to-end detection network를 제안
- 모든 객체를 한번에 예측
- 수작업(앵커나 NMS같은 작업) 컴포넌트가 없기 때문에 간단한 파이프라인을 가짐
- COCO dataset에 대해서 Faster R-CNN baseline 급의 정확도와 런타임 성능을 보임
- Large object에 대해 좋은 퍼포먼스, Small object대해서는 낮은 퍼포먼스를 보임
참조
Object Detection in 20 Years: A Survey
Object detection, as of one the most fundamental and challenging problems in computer vision, has received great attention in recent years.
https://arxiv.org/abs/1905.05055
https://herbwood.tistory.com/18
https://deep-learning-study.tistory.com/504
https://talktato.tistory.com/m/19