Related to: Deep Learning
개요
KITTI Dataset은 단독 카메라와 범위 센서를 사용하여 자율주행 연구를 위해 제공되는 데이터 셋입니다.
KITTI 데이터 셋은 비디오 캡처, 전방 카메라가 장착된 차량, 라이다로 Scan한 Point Cloud, 그리고 상세한 제공 라벨과 메타데이터를 갖고 있습니다.
KITTI 데이터 셋은 고해상도 가로 사진과 정교한 인식 및 추적 데이터 셋, 그리고 자율주행 연구에 사용되는 상세한 라벨과 메타데이터를 갖고 있습니다.
KITTI 데이터 셋의 상세한 라벨과 메타데이터는 3D 객체의 속성, 카메라 및 범위 센서 교정 데이터, 그리고 카메라 매트릭스와 투영 행렬 데이터를 포함하고 있습니다.
KITTI의 홈페이지를 들어가보면 여러가지 Task들이 있고, 그에 따라 다르게 dataset이 주어집니다.
이 글에서는 Monocular 3D Object를 수행하기 위해 필요한 부분만을 다룹니다.
Download Dataset

3D Object Detection Task에 들어가보면 위와 같이 데이터를 다운로드할 수 있는 링크를 제공합니다.
여기서 필요한 항목은 아래와 같습니다.
- left Color Images of object data set (12GB)
- camera Calibration matrices of object data set (16MB)
- training labels of object data set (5 MB)
Hardware 구성
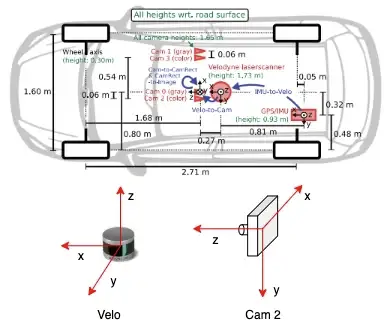
KITTI는 위와 같이 HW를 구성하고 주행하며 데이터를 취득했습니다.
라이다 센서(Velodyne, 이하 라이다 센서)과 카메라 센서의 좌표계 축이 서로 다르기 때문에 주의가 필요합니다.
위 구성을 보면, 카메라들과 센서의 위치가 서로 다른 것을 알 수 있습니다.
각 센서들은 취득하는 데이터의 종류도 Scale도 좌표계 기준도 모두 다릅니다.
만약 라이다 센서로 Scan해서 얻은 3D 공간에서 어떤 물체가 있을 때, 이 물체가 카메라 기준에서의 값은 얼마인지 궁금하다면 좌표계 변환이 필요합니다.
KITTI에서는 아래 논문에서 제시한 방법으로 Camera간의 좌표계 변환과 Camera와 라이다 간의 좌표계 변환 등에 필요한 계수를 추정했습니다.
→ Automatic Camera and Range Sensor Calibration using a single Shot
KITTI 3D BBox Coordinate

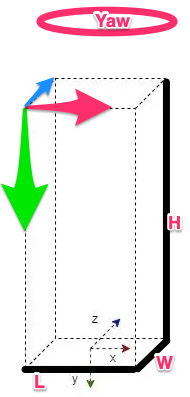
- x-axis → right (length), y-axis → bottom (height), z-axis → forward (width)
- 3B bb corner coordinates in camera coordinate frame, coordinate system is at the bottom center of the box.
KITTI Object’s Property
- label (str)
- 차, 보행자 등의 라벨 정보 문자열
- ‘Car’, ‘Pedestrian’, …
- truncation (float)
- 이미지상에서 물체가 잘려있는 정도
- 0.0 : 전혀 잘리지 않음 ~ 1.0 완전히 잘림
- occlusion (int)
- 폐섹 수준(camera 시야 기준으로 추측 됨), 물체가 가려진 정도
- 0:전혀 가려지지 않음 | 1:부분적으로 가려짐 | 2:완전히 가려짐 | 3:알 수 없음
- alpha (float)
- 관측각, 관측자(자율주행자동차) 기준 물체가 위치한 각도
- -pi:좌측 ~ 0:정면 ~ pi:우측
- xmin (float)
- image 상에서 물체를 감싸는 2d bbox의 left-x
- ymin (float)
- image 상에서 물체를 감싸는 2d bbox의 top-y
- xmax (float)
- image 상에서 물체를 감싸는 2d bbox의 right-x
- ymax (float)
- image 상에서 물체를 감싸는 2d bbox의 bottom-y
- Height (float) (y)
- Camera 좌표계 상에서 물체의 높이(in meters)
- Width (float) (z)
- Camera 좌표계 상에서 물체의 너비(in meters)
- Length (float) (x)
- Camera 좌표계 상에서 물체의 길이(in meters)
- tx (float)
- Camera 좌표계 상에서 물체의 x(in meters)
- ty (float)
- Camera 좌표계 상에서 물체의 y(in meters)
- tz (float)
- Camera 좌표계 상에서 물체의 z(in meters)
- ry (float)
- Camera 좌표계 상에서 물체의 yaw
- -pi:좌측 ~ 0:정면 ~ pi:우측
Vision meets Robotics: The KITTI Dataset
Info
Calibration data
Calibration data는 촬영 날짜 별로 존재
- s(i) ∈ N2 : 원본 이미지 크기 (1392×512)
- K(i) ∈ R3×3 : 교정 매트릭스(unrectified)
- d(i) ∈ R5 : 왜곡 계수(unrectified)
- R(i) ∈ R3×3 : 카메라 0에서 카메라 i로 회전
- t(i) ∈ R1×3 : 카메라 0에서 카메라 i로 변환
- s(i) ∈ N2 : 정류 후 이미지 크기 rect
- R(i) rect ∈ R3×3 : 회전 행렬 정류
- P(i) rect ∈ R3×4 : 정류 후 투영 행렬
KITTI Coordinate Transformations
A guide on how to navigate between different sensor coordinate systems of KITTI.
https://towardsdatascience.com/kitti-coordinate-transformations-125094cd42fb
GAC3D: improving monocular 3D object detection with ground-guide model and adaptive convolution
Monocular 3D object detection has recently become prevalent in autonomous driving and navigation applications due to its cost-efficiency and easy-to-embed to existent vehicles.
https://peerj.com/articles/cs-686/
The KITTI Vision Benchmark Suite
We thank Karlsruhe Institute of Technology (KIT) and Toyota Technological Institute at Chicago (TTI-C) for funding this project and Jan Cech (CTU) and Pablo Fernandez Alcantarilla (UoA) for providing initial results.
https://www.cvlibs.net/datasets/kitti/