Related to: Deep Learning
GAN
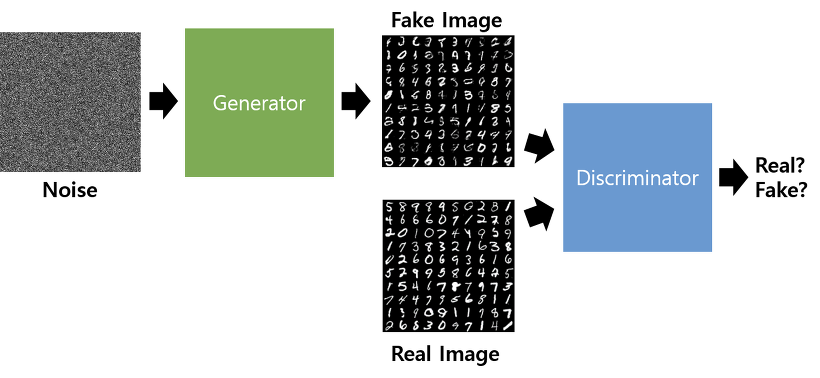
GAN(Generative Adversarial Network)은 인공신경망(Artificial Neural Network)을 사용하여 데이터의 분포를 모방하는 새로운 방식의 기계학습 기법입니다. 데이터 분포를 모방하는 것은 신경망의 핵심 기능입니다.
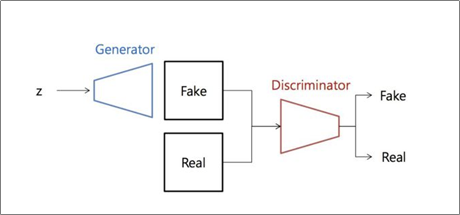
GAN은 데이터를 생성하는 generator와 데이터를 구별하는 Discriminator로 이루어져 있습니다.
-
Generator는 최대한 실제처럼 보이는 데이터를 생성하여 Discriminator를 속이려고 시도합니다.
-
Discriminator는 실제 데이터와 만들어진 가짜 데이터를 구별하려고 시도합니다.
-
두 네트워크는 서로 경쟁하며, 결과적으로 Generator가 데이터의 분포를 잘 모방하게 됩니다.
GAN의 Loss(Objective Function)
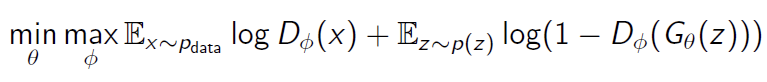
- Discriminator는 위 식에서, D(x)를 최대한 1에 가깝게 만들고 D(G(z))를 최대한 0에 가깝게 만듦으로써 Objective Function을 최대화하는 것을 목적으로 합니다.
- Generator는 위 식에서 D(G(z))를 최대한 1에 가깝게 만듦으로써 Objective Function을 최소화하는 것을 목적으로 한다.
GAN을 학습하면 실제로는 학습이 잘 되지 않는 경우가 있습니다.
Generator의 성능이 안 좋을 때, 위 Loss를 사용하면 Gradient가 굉장히 작아서 학습이 빠르게 될 수 없기 때문입니다.
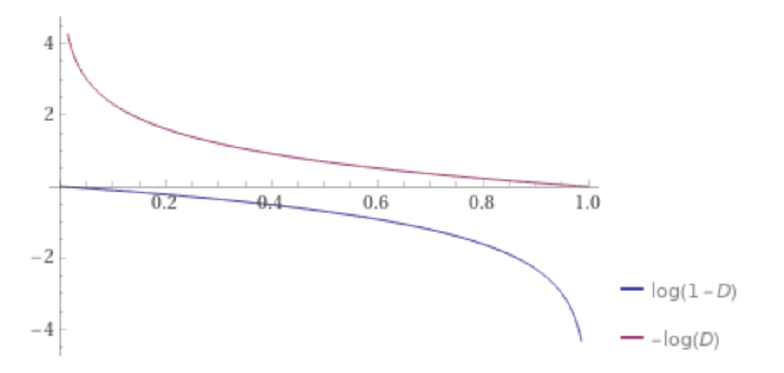
위 그래프를 보면, log(1−D)이 0에 가까울 때(=D(G(z))가 0에 가까울 때) Gradient가 0에 가깝기 때문에 학습이 잘 되지 않을 수 있습니다.
이 경우, 대신에 를 loss로 사용합니다. 기존 loss와 유사한 의미를 갖고 있으면서도 Generator가 학습되지 않았을 때(=D(G(z))가 0에 가까울 때)의 gradient가 크기 때문에 학습이 비교적 잘 될 수 있습니다.
Mode-Collapse

Mode-Collapse는 학습의 불균형으로 발생합니다. Gernerator와 Discriminator중 하나가 학습이 너무 잘 되서 다른 하나의 학습이 안되는 것을 의미합니다.
- discriminator가 너무 학습이 잘 되어서 완벽하게 generate된 이미지를 구분할 수 있는 경우를 생각해보도록 하겠습니다. generator는 어떠한 이미지를 내더라도 discriminator를 속일 수 없고, 더이상 학습이 진행이 되지 않을 것입니다.
- 반대의 경우도 마찬가지 입니다. 한쪽이 너무 잘 되어버리면 다른쪽은 학습이 더이상 진행이 되지 않고 멈추어버리게 됩니다. 이렇게 되면 generator는 한 종류의 이미지만 계속 생성하게 됩니다.
참조
https://proceedings.neurips.cc/paper/2014/file/5ca3e9b122f61f8f06494c97b1afccf3-Paper.pdf
https://pseudo-lab.github.io/Tutorial-Book/chapters/GAN/Ch1-Introduction.html
https://yamalab.tistory.com/98
https://process-mining.tistory.com/169
https://raon1123.blogspot.com/2019/10/gan-model-collapse.html