Related to: Deep Learning
개요
“Deep Back-Projection Networks For Super-Resolution” 논문은 딥 백프로젝션 네트워크를 사용하여 이미지 초해상도를 개선하는 새로운 방법을 제안합니다. 이 논문의 저자들은 딥 컨볼루션 신경망을 기반으로 한 이전 방법들이 인식 품질이 낮고 재구성된 이미지에서 고주파수 세부 정보가 부족하다는 한계점이 있다고 주장합니다.
제안된 방법은 전방향 및 역방향 투영을 결합하여 초기 예측을 개선하는 데 역방향 투영이 사용됩니다. 이러한 접근 방식은 고주파수 세부 정보를 더 잘 재구성하고 재구성된 이미지의 인식 품질을 개선하는 데 도움이 된다는 것을 저자들은 주장합니다.
실험 결과는 제안된 방법이 객관적인 측정 기준과 주관적인 인식 품질 측면에서 최첨단 방법보다 우수하다는 것을 보여줍니다. 또한, 저자들은 제안된 방법이 다양한 수준의 노이즈와 압축 아티팩트에 대해 강건하다는 것을 입증하였습니다.
구조를 살펴보면, 내부적으로 Conv 연산을 이용하여 downscale, Deconv를 사용하여 upscale을 수행합니다. 그리고 이 결과에 반대 연산(Conv를 사용했다면 Deconv, Deconv를 사용했다면 Conv)를 다시 적용하여 입력과의 차이를 구합니다.(Feed-Back)
이 차이 값에 다시 Conv 연산을 사용하여 Feature를 추출하며, 이 과정을 반복합니다. 이 때, 입력과 출력의 크기는 동일하게 유지되기 때문에 이미지 크기을 키울 수 없습니다.
이에 저자는 x2, x4, x8을 하기 위해 각각 Kernel Size, Stride, Padding을 조정하여 영상의 크기를 키웁니다.
1. Introduction
Single Image SR은 Low Resolution에서 High Resolution Image로의 비선형 Mapping을 구하는 과정입니다. 인간의 시각 시스템은 단순한 Feed-Forward가 아닌 Feed-Back 연결이 있다고 여겨집니다. 저자는 Feed-Forward SR 모델들의 성능이 부족한 이유가 이런 Feed-Back 연결의 부족으로 추측했습니다.
반면 Feed-Back 형식의 연결은 초기 SR 알고리즘 중의 하나이며 좋은 성능을 내는 것이 입증되었지만 Iteration 수, Blur Operator 등의 파라메터 선택에 결과가 민감하게 변화합니다.
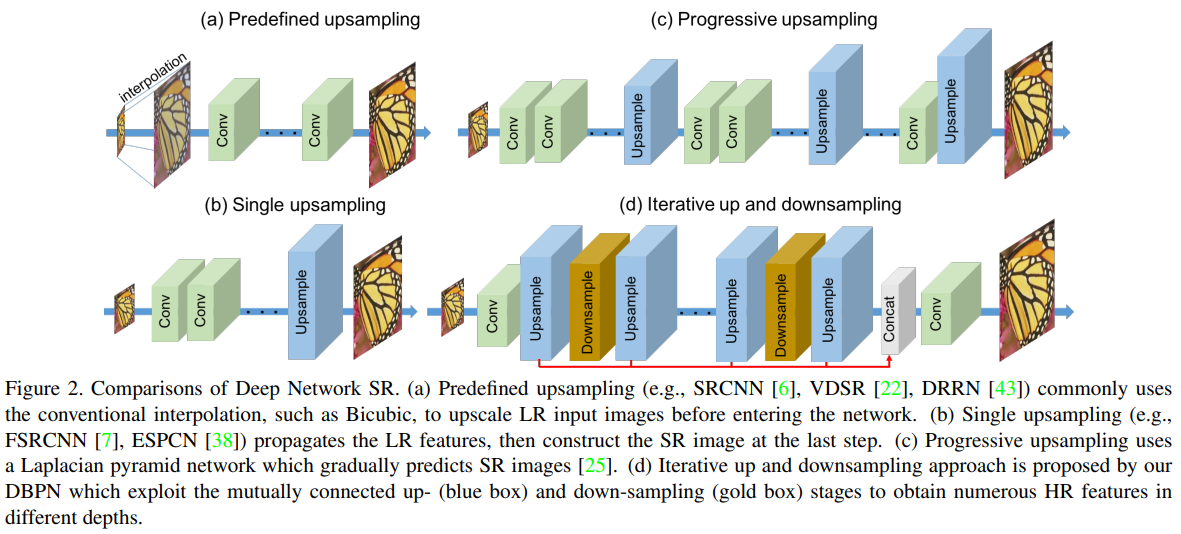
저자는 ‘Improving Resolution by Image Registration’ 논문에서 영감을 받아 반복적인 Up, Down Sampling을 통해 Large Scaling Factor(4배, 8배 SR 등)에서도 잘 동작하는 End-to-End 모델을 만들었습니다.
저자가 주장하는 Contribution은 아래와 같습니다.
-
Error Feedback
SR을 위한 Up, Down Sampling 시 Error를 Feed-Back하는 구조
-
상호 연결된 Up, Down Sampling Stage들
기존 Feed-Forward 구조들은 SR 이미지를 매핑하는데 좋은 성능을 보여주지 못했습니다. 특히 Scaling Factor가 클수록 더욱 좋은 성능을 보여주지 못했습니다.
이에 저자는 Upsampling Layer 뿐만 아니라 Downsampling Layer를 사용해 Feature Map을 다시 LR 해상도로 다시 Projection합니다.
-
Deep concatenation
다른 네트워크들과 다르게 Sampling Layer를 통과시키지 않습니다. 그 대신 위 Feature 2.의 붉은 선처럼 각 Upsampling Stage에서 얻은 HR Feature를 Concatenation하여 마지막에 Conv를 수행하는 방식으로 결과를 얻습니다.
-
Improvement with dense connection
Upsampling Stage에서 얻은 HR Feature를 다음 Stage에서 활용합니다.
2. Related Work
논문과 관련된 선행 연구들을 다루는 항목이므로 생략합니다.
3. Deep Back-Projection Networks
HR Image(M x N)
LR Image(M’ x N’), M’ < M, N’ < N
위와 같이 정의했을 때, DBPN은 LR → HR, HR → LR Projection을 모두 수행합니다.
3.1 Projection Units
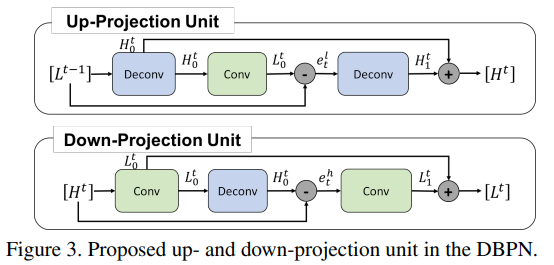
Up Projection은 다음과 같이 정의됩니다.
(Up Projection을 위한 수식 및 정의가 기술되어 있지만, 코드로 대체합니다)
class UpBlock(torch.nn.Module):
def __init__(self, num_filter, kernel_size=8, stride=4, padding=2, num_stages=1, bias=True, activation='prelu', norm=None):
super(UpBlock, self).__init__()
self.conv = ConvBlock(num_filter*num_stages, num_filter, 1, 1, 0, activation, norm=None) if num_stages > 1 else torch.nn.Identity()
self.up_conv1 = DeconvBlock(num_filter, num_filter, kernel_size, stride, padding, activation, norm=None)
self.up_conv2 = ConvBlock(num_filter, num_filter, kernel_size, stride, padding, activation, norm=None)
self.up_conv3 = DeconvBlock(num_filter, num_filter, kernel_size, stride, padding, activation, norm=None)
def forward(self, x):
x = self.conv(x)
h0 = self.up_conv1(x)
l0 = self.up_conv2(h0)
h1 = self.up_conv3(l0 - x)
return h1 + h0Down Projection은 다음과 같이 정의됩니다.
(마찬가지로, 코드로 대체합니다)
class DownBlock(torch.nn.Module):
def __init__(self, num_filter, kernel_size=8, stride=4, padding=2, num_stages=1, bias=True, activation='prelu', norm=None):
super(DownBlock, self).__init__()
self.conv = ConvBlock(num_filter*num_stages, num_filter, 1, 1, 0, activation, norm=None) if num_stages > 1 else torch.nn.Identity()
self.down_conv1 = ConvBlock(num_filter, num_filter, kernel_size, stride, padding, activation, norm=None)
self.down_conv2 = DeconvBlock(num_filter, num_filter, kernel_size, stride, padding, activation, norm=None)
self.down_conv3 = ConvBlock(num_filter, num_filter, kernel_size, stride, padding, activation, norm=None)
def forward(self, x):
x = self.conv(x)
l0 = self.down_conv1(x)
h0 = self.down_conv2(l0)
l1 = self.down_conv3(h0 - x)
return l1 + l0Up Projection과 Down Projection Unit 한 쌍를 한 Stage로 표현하며, 이 Projection을 Unit들은 Projection Error를 얻을 수 있게 됩니다. 또한 이 Projection Unit들은 Projection Error를 반복적으로 Feed-Back함으로써, 스스로 자가교정 절차로 이해할 수 있습니다.
또한 기존의 모델들은 수렴속도가 느려지고 최적의 결과를 주지 않는 문제들 때문에 8x8, 12x12 등의 큰 Filter Size를 지양했습니다. 그러나 이 Projection Unit은 이러한 문제들을 억제하고, 얕은 네트워크에서도 더 좋은 결과를 얻게 해줍니다.
3.2 Dense Projection Units
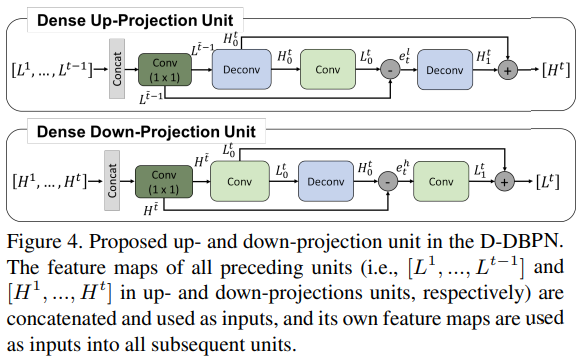
DenseNets를 통해 Dense Inter-Layer Connectivity Pattern이 Vanishing Gradient 문제를 완화하고 Feature 향상 등 장점을 가지는 것이 밝혀졌습니다. 저자는 이것에 영감을 받아 DBPN에 Dense Connection을 추가했으며, 이를 D-DBPN으로 명명했습니다.
다만 기존 DenseNets에서 사용한 구조와 조금 다른데 Dropout과 Batch Norm을 사용하는 것은 SR Task에 적합하지 않아서 사용을 지양했습니다. (이유는 이 논문에 기술되어 있습니다)
또한 1x1 Conv Layer를 사용하여 Feature를 Pooling하고 Dimension을 감소시킨 뒤 Projection을 수행했습니다.
3.3 Network Architecture
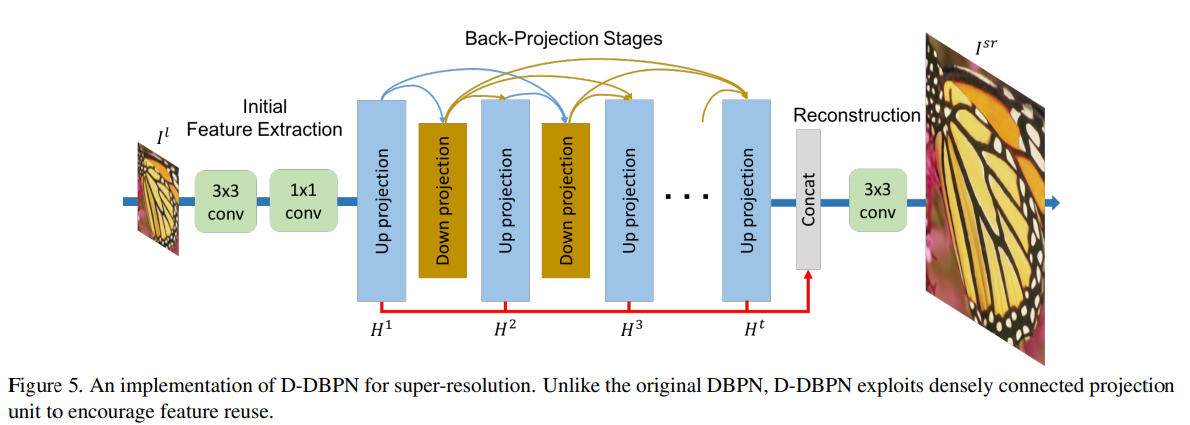
D-DBPN의 구조는 위 그림과 같고, 크게 3개의 구조로 나눌 수 있습니다.
-
Initial Feature Extraction
Conv 연산을 통해 Feature를 추출합니다.
-
Back-Projection Stages
Up-Projection과 Down-Projection을 번갈아가며 수행하며 각각 HR, LR Feature들을 추출합니다.
-
Reconstruction
각 HR Feature들을 Concatenation 하고, Conv를 사용하여 최종적인 결과 이미지를 생성합니다.
4. Experimental Results
4.1 Implementation and training details
제안된 네트워크로 Up-Scaling을 하기 위해서는 Scaling factor(몇 배로 이미지를 키울 것인지)에 따라서 Filter Size와 기타 파라메터가 정의됩니다. Scaling factor에 따른 파라메터는 깃허브 코드를 참조했으며, 다음과 같습니다.
- Scaling Factor : x2
- Kernel Size : 6 x 6
- Stride : 2
- Padding : 2
- Scaling Factor : x4
- Kernel Size : 6 x 6
- Stride : 2
- Padding : 2
- Scaling Factor : x8
- Kernel Size : 6 x 6
- Stride : 2
- Padding : 2
Weight의 초기화는 카이밍 히(Kaiming He)가 제안한 He Initialization을 사용했습니다.
훈련의 경우 DIV2K, Flickr, ImageNet dataset을 사용했으며 augmentation은 적용하지 않았습니다.
LR 이미지의 생성은 Bicubic을 사용해서 데이터셋의 원본 이미지를 Downscaling하여 생성했습니다.
훈련에 사용한 다른 설정들은 다음과 같습니다.
- Batch size : 20
- Input : 32 x 32
- Output : Scaling Factor에 따라 변화. Factor가 2일 경우 64 x 64
- Epoch : 10
- Optimizer : Adam
- Lr : 1e-4
- 매 500000 Epoch 마다 0.1배로 감소시킴
- momentum : 0.9
- weight decay : 1e-4
- Lr : 1e-4
4.2 Model Analysis
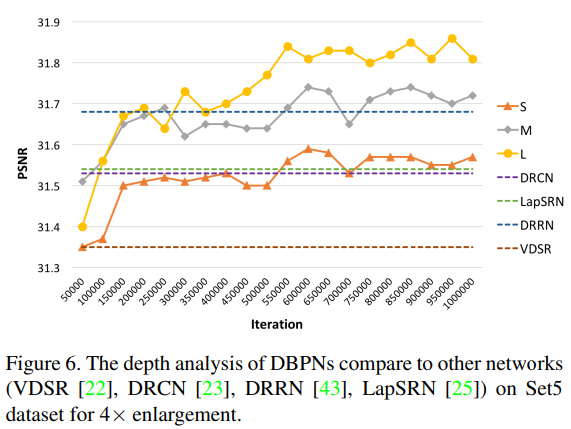
성능을 확인하기 위하여 여러 크기의 네트워크(Small, Midium, Large)를 구성하였고, State-of-art Model 보다 우수한 결과를 보여주었습니다.
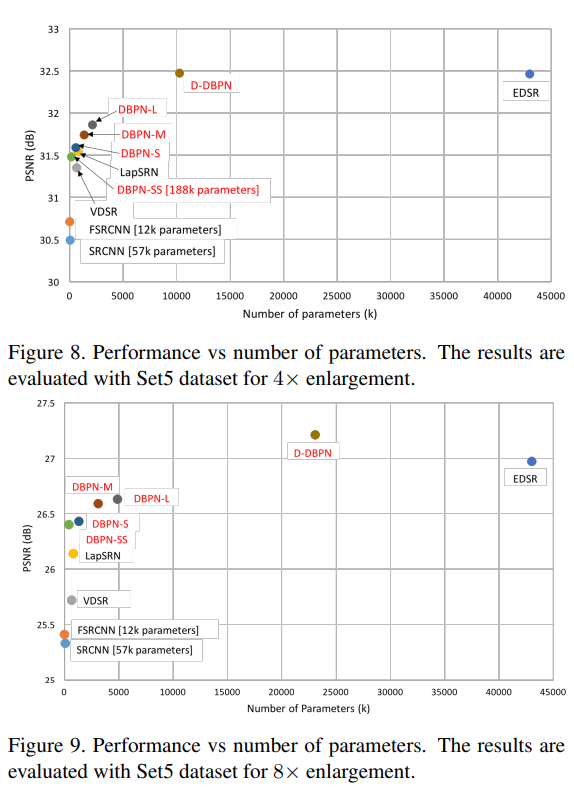
추가로 DBPN-SS(Small보다 더 가벼운 버전)을 만들어 실험하였고 마찬가지로 우수한 성능을 보였습니다. 또한 기존 모델들보다 더 적은 Parameter로 더 좋은 결과를 얻을 수 있는 것을 실험적으로 입증하였습니다.
D-DBPN의 경우, Parameter 수가 많이 증가하지만 제일 좋은 성능을 보였습니다. 특히 x8 Upscaling의 경우, 기존의 다른 방법보다 월등이 뛰어난 결과를 보여줍니다.
5. Conclusion

Single Image Super Resolution을 위한 ‘DBPN’ 네트워크를 제안했고 기존 방법들과 다르게 여러번의 up sampling, down sampling step들을 통해 SR 결과 이미지를 생성합니다.
또한 제안한 네트워크는 다른 State-of-the-art 방법보다 x8 Upscaling 요소에서 훨신 더 좋은 성능을 보여줍니다.
아래 Table은 다른 State-of-the-art SR 알고리즘과의 성능 비교 표 입니다. 매우 많은 parameter가 필요한 EDSR에 근접하거나 혹은 그 이상의 성능을 보여줍니다.
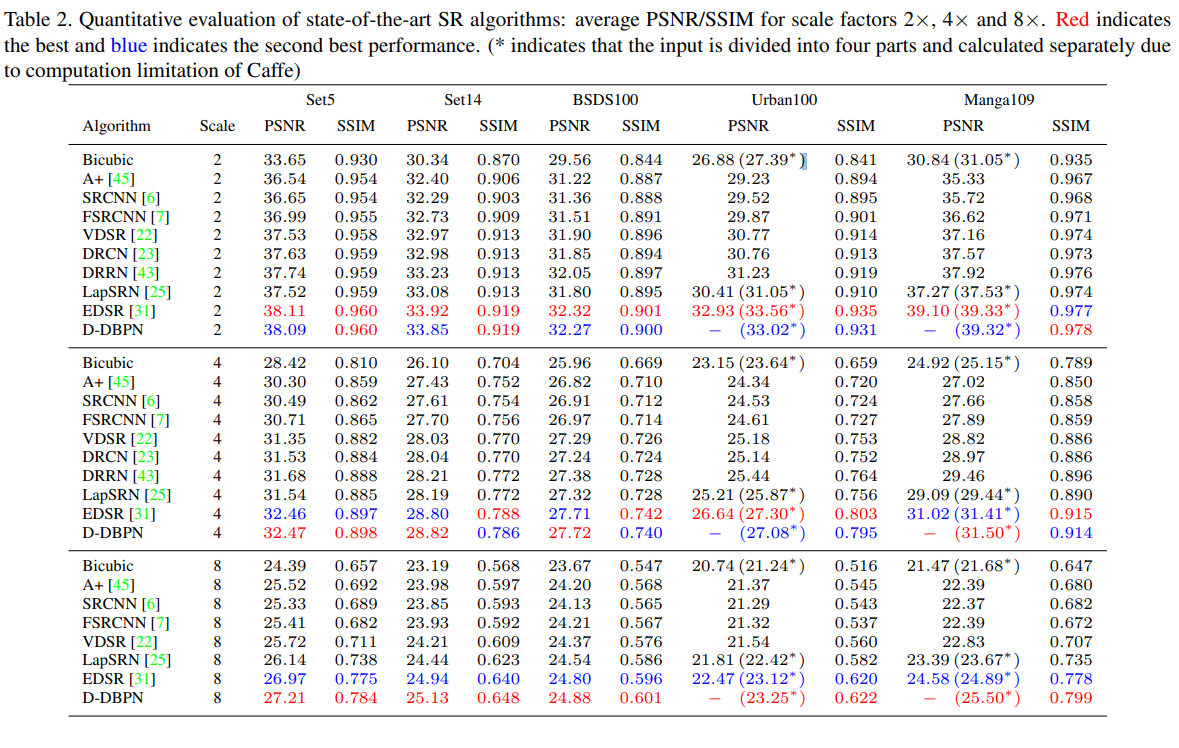
참조
https://arxiv.org/abs/1803.02735