Related to: Deep Learning
개요
같이 스터디를 하는 분들과 Kaggle - BirdCLEF2023에 참가하게 되었습니다. 이전에 개최되었던 비슷한 대회들을 찾아본 결과, BirdNET이 높은 성능을 보였음을 확인했습니다.
이에 BirdNET을 기본으로 실험을 진행하고자 논문을 읽고 이곳에 정리합니다.
BirdNET: A deep learning solution for avian diversity monitoring
Abstract
공간 및 시간에 따른 조류 다양성의 변화는 환경 변화를 평가하는 지표로 사용됩니다. 기존에는 전문가가 이러한 데이터를 수집했으나, 수동적으로 수집한 음향 데이터가 대체 조사 기법으로 떠오르고 있습니다. 하지만 대규모 Audio Dataset에서 정확한 종 풍부도 Data를 추출하는 것은 어려운 일이었습니다.
그러나 최근 DNN의 발전은 음향 이벤트 감지 및 분류 분야에서 기존의 신호처리를 능가하는 성능을 발휘하는 경우가 많습니다.
이에 저자는 BirdNET이라고 하는 984개의 북미 조류 및 유럽 조류를 소리로 분류할 수 있는 Network를 제안합니다.
BirdNET은 ResNet에서 파생되었으며 광범위한 데이터 전처리, 증강 및 혼합을 사용하여 학습되었습니다.
BirdNET은 3개의 Dataset에 대하여 평가되었습니다.
- 22960개의 단일 종 녹음
- 연구자들이 현장에서 조류 다양성을 측정하는데 사용하는 도구와 유사한 설계의 자율 녹음 장치 배열로 수집한 286시간 분량의 완전 Labeling된 사운드스케이프 Data
- 전문 조류 관잘차들이 자주 찾는 4개의 eBird 핫스팟 근처에 배치한 단일 고품질 무지향성 미이크의 33,670 시간 분량의 사운드스케이프 데이터
여기서 저자는 노이즈, 겹치는 발성에 대응하려면 도메인 별 데이터 증강이 핵심이라는 사실과 입력 Spectrogram을 고해상도로 만들수록 분류 성능을 올릴 수 있다는 것을 발견했습니다.
소개
생태계의 건강을 평가하는 것이 중요하며, 이에 조류는 대부분의 환경에 서식하기 때문에 모니터링 대상으로 널리 활용된다고 합니다.
이를 기반으로 어디에 어느 종이 얼마나 사는지 파악하는 것의 중요성을 이야기하며, 이를 위해 환경 소리를 녹음하는 작업이 어떻게 이루어지며 어떤방식으로 발전했는지 소개합니다.
그리고 딥러닝을 사용하기 이전에 BirdCLEF 챌린지에 어떤 솔루션들이 사용되었는지 소개합니다.
마지막으로 스펙트로그램을 이용한 CNN 분류기를 사용하는 방식이 당시 가장 좋은 성능냈음을 보여주며, 몇 개의 레이어만 있는 잘 설계된 얕은 네트워크가 일반적인 이미지 분류에 사용되는 깊은 네트워크와 비슷한 성능을 내는 결과를 통해 조류의 발성과 같이 매우 많은 Sound Class를 분류하기 위해서는 새 소리의 전반적인 특성과 디테일한 특성들 모두 동등하게 중요하다고 주장합니다.
방법
저자가 훈련에 사용하기 위해 데이터를 선별하는 과정을 설명하고, 최종적으로 어떤 데이터들이 포함됬는지 소개합니다.
추가로, 기존에 가장 일반적인 FP Detection 결과가 다른 동물이나 곤충의 소리 혹은 다른 환경 잡음이었으므로 구글(Stowell and Plumbley, 2013) 및 WarblR Dataset에서 다른 데이터셋에서 노이즈로 판단해야 하는 소리들을 가져와 ‘기타 동물’, ‘사람’, ‘환경 소음’ 세 가지로 분류하여 사용했습니다.
스펙트로그램의 경우 해상도가 중요하기 때문에 아래 파라미터를 사용했습니다.
- FFT Window Size : 10.7ms(512 Samples at 48kHz Sampling Rate)
- Overlap : 25%
- 1 Frame = 8ms
또한 대부분의 새 발성 주파수는 250Hz ~ 8.3kHz 사이로 제한되는데, 스펙트로그램의 주파수 범위를 대부분의 조류 발성 주파수 범위를 포함하면서도 데이터 증강 중에 피치 이동을 위한 여지를 남겨두기 위해 150Hz~15kHz의 값으로 제한했습니다.
또한 선행 연구 결과에 의거해 500Hz까지 대략적인 선형 스케일링을 달성하기 위해 64개 대역과 1750Hz의 중단 주파수를 가진 멜 스케일을 이용하여 주파수 압축을 수행하여 씨그러운 환경에서 새의 울음소리를 분류를 더 잘 되도록 하였습니다.
데이터당 소리의 길이는 경험적으로 3초로 하였으며, 데이터에서 새들은 평균 1.94초 정도의 울음소리를 냅니다.
데이터 증강
저자는 아래 3개 방식으로 데이터를 증강 했습니다.
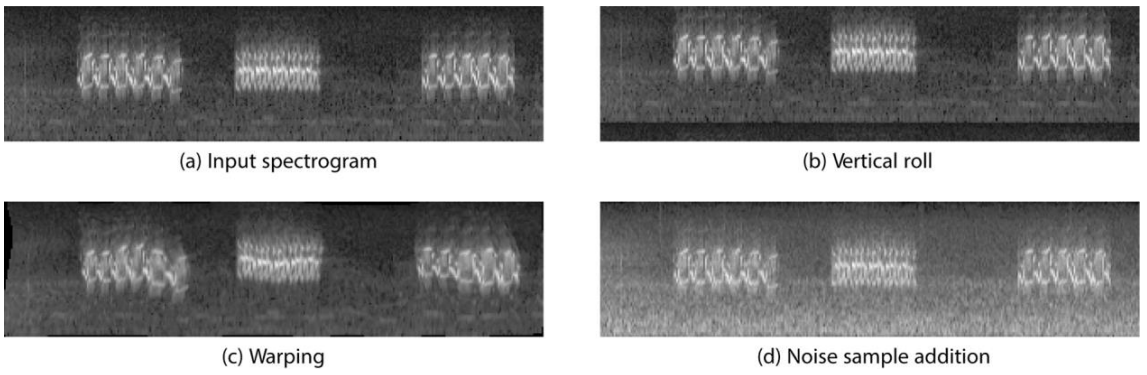
- Vertical Roll (p=0.5)
- 멜스펙트로그램이므로, 수직방향 이동은 주파수를 바꾸는 것을 의미합니다.
- 모든 평가 시나리오에서 점수가 향상되었다고 합니다.
- Wraping (p=0.5)
- 사람의 음성 인식에서 널리 사용되는 기법입니다.
- Noise Sample Addition (p=0.5)
- 새 소리가 없는 음원에서 추출한 BG Noise를 무작위 가중치로 합성하는 방식입니다.
- 가장 강력한 증강 방법이라고 합니다.
모델 아키텍쳐
BirdNET은 ResNet을 기반으로 합니다. 저자는 K=4(네트워크 폭), N=3(네트워크 깊이)로 네트워크를 구축했습니다.
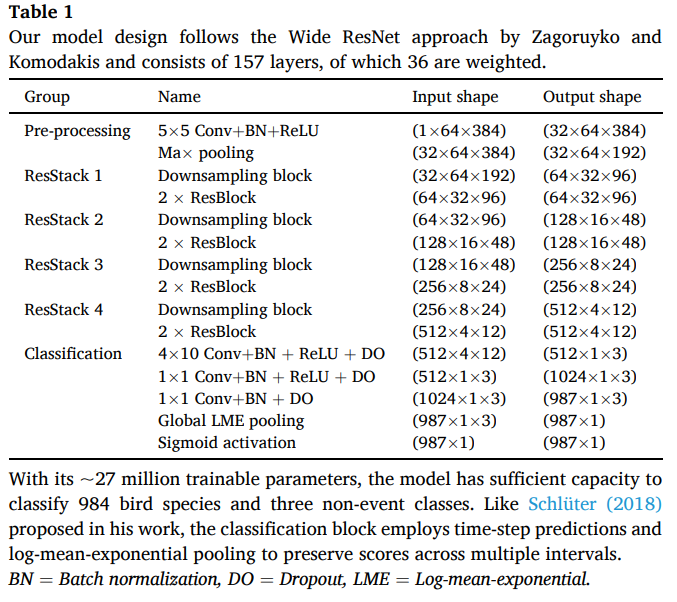
- Pre-Processing Group : 5x5 단일 Conv와 1x2 max pooling을 수행합니다.
- ResStack Group : Feature Extraction을 수행합니다.
- Downsampling Block은 여기에서 제안한 방법을 사용합니다.
- ResBlock은 원본 Wide ResNet의 설계를 따릅니다.
- Classification Block : 분류를 수행합니다.
Train
Class Imbalance를 해결하기 위해 Oversampling을 수행했습니다.
Focal Loss의 경우 모델 성능을 향상시키지 못했습니다.
동시에 발성하는 조류 종을 시뮬레이션 하기 위해 최대 3개의 스펙토그램을 하나의 샘플에 무작위로 결합하는 Mix-Up을 사용했습니다.
Optimzier는 Adam을 사용했으며 Lr은 1e-3, Batch Size는 32를 사용했습니다.
Scheduler의 경우 valid loss가 감소하지 않을 경우 0.5배씩 낮추는 방식을 사용했습니다.
Dropout의 경우 0.5를 초기값으로 Scheduler가 Lr를 줄일 때 마다 0.1씩 줄였습니다.
3 Epoch이상 성능 향상이 없다면 훈련을 종료하도록 Eearly Stoping을 적용했습니다.
결과
샘플별 평균 정밀도(mAP)와 Class 별 평균 정밀도(cmAP)를 Metric으로 사용하여 시스템을 평가했습니다. mAP는 일반적인 종에 더 높은 순위를 부여하므로 Class Imbalance에 대해 이점을 얻었지만, cmAP는 Class 별로 정밀도를 구한 것의 평균이기 때문에 모든 Class를 잘 맞춰야 합니다.
(이하 생략, 저자의 모델로 데이터셋들에 대한 결과를 평가하고 결론을 맺습니다.)
훈련 과정에서 저자가 성능향상을 얻은 포인트는 아래와 같습니다.
- 입력 스펙트로그램의 높은 시간 분해능(짧은 FFT Window Length)를 사용하여 성능을 향상했습니다.
- Mix-Up을 사용한 다중 Label 분류는 모든 Dataset에 대해 성능 향상을 얻었습니다.
- 더 깊은 토폴로지(더 많은 레이어)가 더 넓은 토폴로지(더 많은 필터)보다 반드시 더 나은 성능을 발휘하는 것은 아닙니다.
- Over Sampling을 제외하면, Class Imbalance에 대해 전체 점수를 개선하지 못했습니다.