Related to: Deep Learning
Adam에 앞서 알아야 할 Optimizer
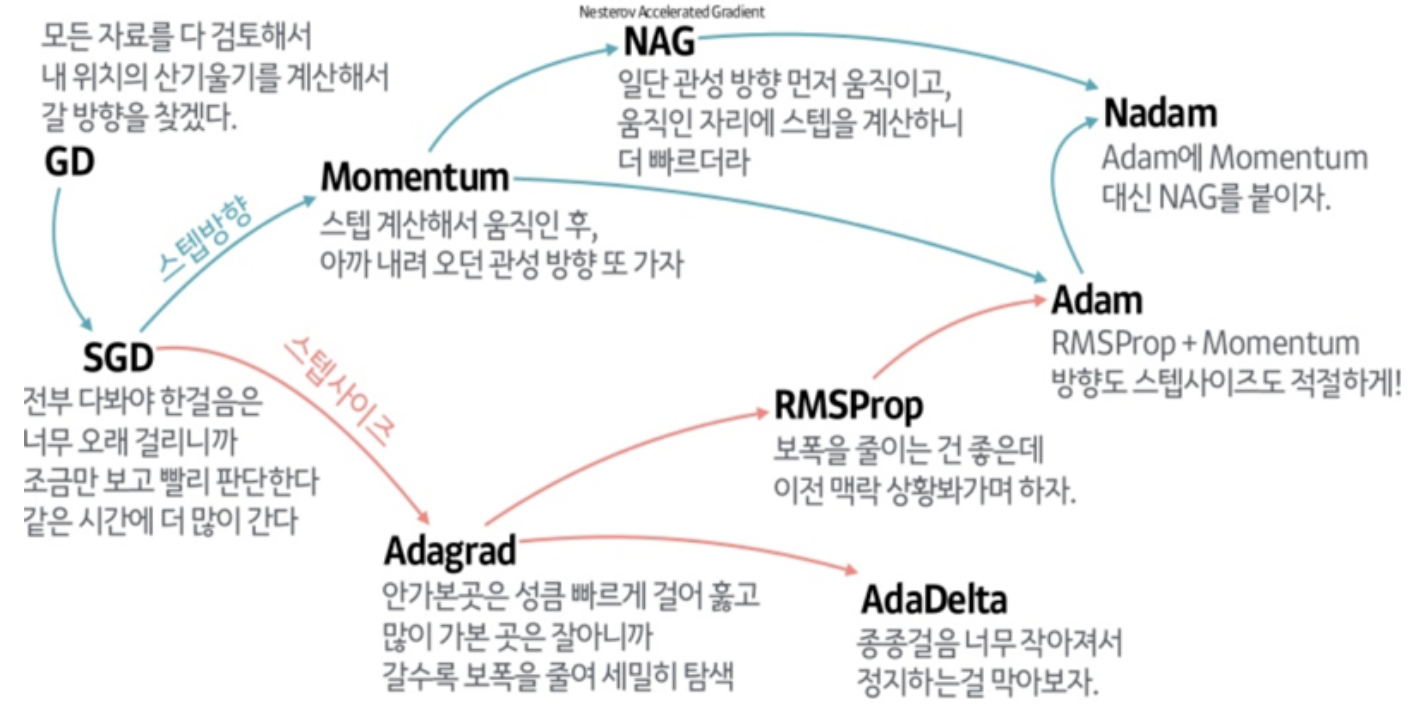
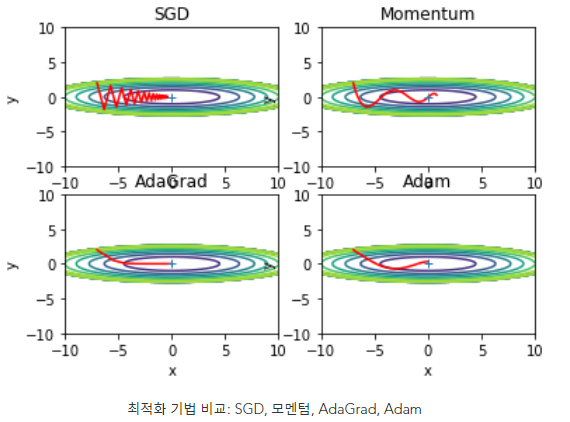
-
Basic Gradient Descent
== : Calculate Gradient & Parameter Update==
- : model’s parameter at the step t
- : Loss Function
- : Learning Rate
- : Partial Derivative for theta
-
Momentum : 이전의 Gradient를 곱하여 추가로 더합니다.
하지만 이전 값을 기억해야 하기 때문에 기존 대비 2배의 메모리가 필요합니다.
== : Calculate Gradient==
== : Parameter Update==
- : Momentum term, 0.9
- : Momentum Update at the step t
-
AdaGrad(Adaptive Gradient) : Parameter별로 다른 학습률을 적용합니다.
Gradient가 커서 변화가 많은 Parameter는 학습률을 감소시켜 다른 변수들이 잘 학습되도록 합니다.
== : Calculate Size of the Gradient==
→ 학습이 진행될 때 마다 계속해서 gradient를 누적해서 더하기 때문에, 분모항이 계속 커지게 됩니다. 따라서, 점점 학습이 이루어지지 않습니다.
== : Parameter Update==
- : Gradient Size
- : A very small value to add to prevent from going to zero
-
RMSProp : AdaGrad와 같은 컨셉이지만, 누적 합이 아닌 지수 평균을 사용합니다.
변수 간의 상대적 학습 차이를 유지하면서, g가 무한정 커지는 것을 막아 오래 학습할 수 있습니다.
== : Calculate Size of the Gradient==
== : Parameter Update==
- : Update Rate, 0 ~ 1
Adam(Adaptive Moment Esimation)
Adam은 Momentum 와 RMSProp의 장점을 결합한 알고리즘 입니다.
== : Calculate Size of the Gradient==
== : Calculate Gradient==
== : Bias Correction for ==
== : Bias Correction for ==
== : Parameter Update==
Bias Correction
Adam의 Bias Correction 은 update에 사용하는 각 Term이 0으로 편향되는 것을 보정하기 위해 사용합니다.
Gradient Descent with Momentum, RMSProp, ADAM은 모두 beta<1 값을 이용해 이전 값들을 서서히 잊어가는 Exponentially Weighted Moving Average (EWMA)의 일종이라고 할 수 있습니다.
EWMA는 일반적으로 아래와 같은 수식으로 쓸 수 있습니다.
beta는 이전 값을 얼마나 기억할지를 의미하므로 1에 가깝게 설정할수록 Smoothing이 많이 됩니다.
다만, 위 영상과 같이 Smoothing을 키울수록 초기 time의 Smoothing 결과가 원래 데이터들의 포인트에 비해 낮게 나오는 것을 알 수 있습니다. (0으로 편향됩니다)
이 때, 아래 수식을 사용하여 보정할 수 있습니다.
Adam에서, Bias Correction을 사용한 경우와 사용하지 않은 경우의 예시는 아래와 같습니다.
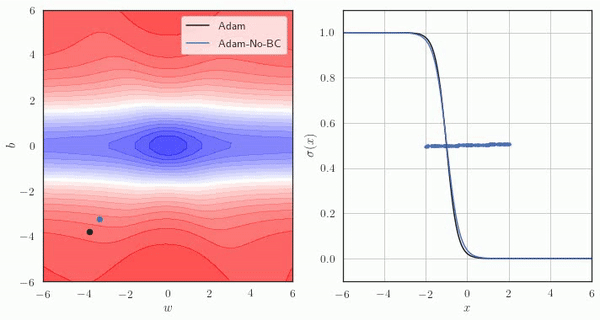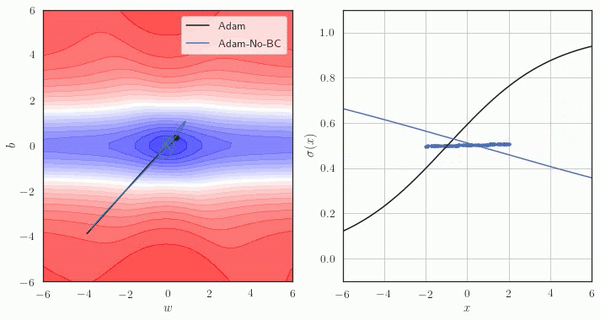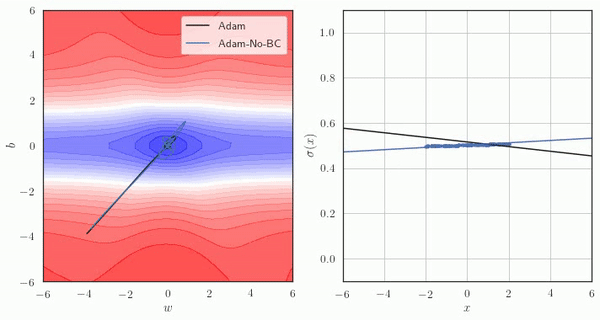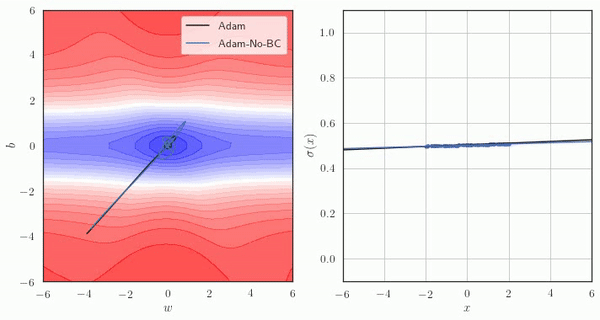
Adam의 문제
Adam의 뛰어난 성능에도 불구하고, 일부 경우에서 Adam이 최적 솔루션으로 수렴하지 않는다는 사실이 밝혀졌습니다.
이를 해결하기 위해서는 SGD와 Mometerm을 사용해야 가능합니다. Adam과 SGD와의 격차를 좁히기 위해 여러 연구가 진행되었고, Nitish Shirish Keskar와 Richard Socher는 ‘Improving Generalization Performance by Switching from Adam to SGD’라는 논문을 통해 Adam으로 훈련 중에 SGD로 전환하는 방식으로 Adam만 사용할 때보다 더 나은 일반화 능력을 얻을 수 있음을 보여주었습니다.
- 저자는 훈련의 초기 단계에서 Adam이 여전히 SGD를 능가하지만 나중에 학습이 포화된다는 것을 발견했습니다.
- 따라서 Adam과 함께 심층 신경망 교육을 시작한 다음 특정 기준에 도달하면 SGD로 전환하는 SWATS라는 전략을 제안했습니다.
참조
Adam: A Method for Stochastic Optimization
We introduce Adam, an algorithm for first-order gradient-based optimization of stochastic objective functions, based on adaptive estimates of lower-order moments.
https://arxiv.org/abs/1412.6980
https://velog.io/@freesky/Optimizer
https://hazel01.tistory.com/36
https://ropiens.tistory.com/90
https://towardsdatascience.com/adam-latest-trends-in-deep-learning-optimization-6be9a291375c
https://angeloyeo.github.io/2020/09/26/gradient_descent_with_momentum.html