Related to: Data Structure
Decision Tree - WIKI
결정 트리(decision tree)는 의사 결정 규칙과 그 결과들을 트리 구조로 도식화한 의사 결정 지원 도구의 일종입니다.
결정 트리는 운용 과학, 그 중에서도 의사 결정 분석에서 목표에 가장 가까운 결과를 낼 수 있는 전략을 찾기 위해 주로 사용됩니다.
Decision Tree - ML
결정 트리(Decision Tree, 의사결정트리, 의사결정나무라고도 함)는 분류(Classification)와 회귀Regression) 모두 가능한 지도 학습 모델 중 하나입니다.
-
Process
-
아래와 같이 데이터를 가장 잘 구분할 수 있는 질문을 기준으로 나눕니다.
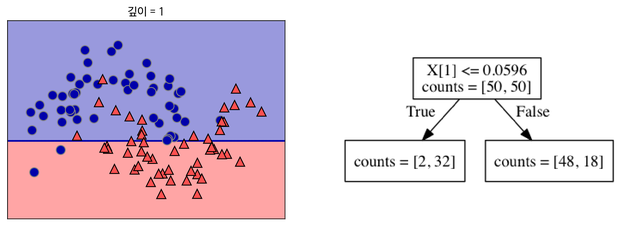
-
나뉜 각 범주에서 또 다시 데이터를 가장 잘 구분할 수 있는 질문을 기준으로 나눕니다.
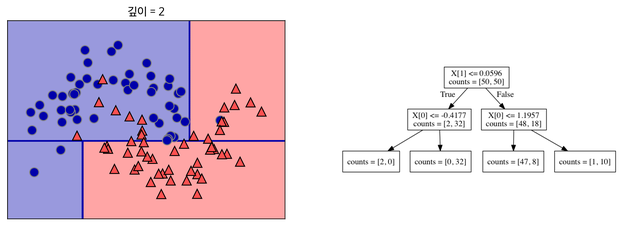
-
이를 지나치게 많이 하면 아래와 같이 오버피팅이 됩니다. 결정 트리에 아무 파라미터를 주지 않고 모델링하면 오버피팅이 됩니다.
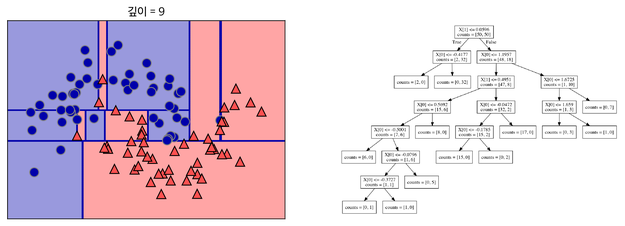
-
가지치기(Pruning)
오버피팅을 막기 위한 전략으로 가지치기(Pruning)라는 기법이 있습니다. 트리에 가지가 너무 많다면 오버피팅이라 볼 수 있습니다. 가지치기란 나무의 가지를 치는 작업을 말합니다.
- min_sample_split
- min_sample_split = 10 : 한 노드에 10개의 데이터가 있다면 그 노드는 더 이상 분기를 하지 않습니다.
- max_depth
- max_depth = 4 : 깊이가 4보다 크게 가지를 치지 않습니다. 가지치기는 사전 가지치기와 사후 가지치기가 있지만 sklearn에서는 사전 가지치기만 지원합니다.
알고리즘: 엔트로피(Entropy), 불순도(Impurity)
- 불순도(Impurity) : 해당 범주 안에 서로 다른 데이터가 얼마나 섞여 있는지를 뜻합니다.
- 순도(Purity) : 불순도와 반대되는 단어입니다.
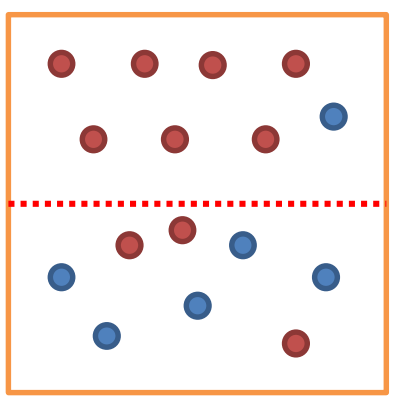
위 그림에서 위쪽 범주는 불순도가 낮고, 아래쪽 범주는 불순도가 높습니다.
바꾸어 말하면 위쪽 범주는 순도(Purity)가 높고, 아래쪽 범주는 순도가 낮습니다.
- 엔트로피(Entropy)는 불순도(Impurity)를 수치적으로 나타낸 척도입니다
- : 한 영역 안에 존재하는 데이터 가운데 범주 i에 속하는 데이터의 비율
정보 획득 (Information gain)
- Information gain
- : Step t 시점에서의 Entropy
- Information gain :
- Step t에서의 Entropy는 분기되어 있을 수 있습니다. 이 경우, 가중평균을 사용하여 Entropy를 계산합니다.
참조
https://ko.wikipedia.org/wiki/결정_트리